
«Big data» — это термин, который описывает большой объем данных – как структурированных, так и неструктурированных, – которые ежедневно наполняют бизнес.
Но важен не объем данных. Важно то, что организации делают с данными. Большие данные могут и должны быть проанализированы с целью принятия лучших решений и стратегических деловых движений.
Финансовые и банковские операции – одни из краеугольных камней этого потока больших данных, и способность быстро и эффективно обрабатывать их дает возможность быть конкурентоспособными среди банков и финансовых учреждений.
Даг Лейни сформулировал нынешнее основное определение больших данных как три составляющие:
Разнообразие – означает множество типов обрабатываемых данных. Банкам приходится иметь дело с огромным количеством различных типов данных. От подробностей и детальной истории транзакций до кредитных баллов и отчетов об оценке рисков у банков.
Скорость – означает скорость, с которой новые данные добавляются в базу. Для респектабельного банка легко достичь порога в 100 транзакций в минуту.
Объем – означает количество места, которое эти данные займут для хранения. Огромные финансовые учреждения, такие как Нью-Йоркская фондовая биржа (NYSE), ежедневно генерируют терабайты данных.
Как используют «Big data» в банковской сфере и почему они так важны:
Определение и анализ структуры расходов клиентов.
Обнаружение основных каналов транзакций (снятие через банкомат, оплата кредитной дебетовой картой).
Разделение клиентов на сегменты в соответствии с их профилями.
Кросс-продажи товаров на основе сегментации клиентов.
Управление и предотвращение мошенничества.
Оценка риска, соответствие требованиям безопасности и отчетности перед регулятором.
Анализ и реагирование на отзывы клиентов.
Модели потребительских расходов
Банки имеют прямой доступ к большому количеству исторических данных о структуре расходов клиентов. Они знают, сколько денег вам перевели в качестве заработной платы за данный месяц, сколько ушло на ваш сберегательный счет, сколько ушло вашим поставщикам коммунальных услуг и т. д.
Это обеспечивает обширную основу для дальнейшего анализа. Применяя фильтры, такие как праздничные сезоны и макроэкономические условия, банковские работники могут понять, стабильно ли растет зарплата клиента и остаются ли расходы адекватными. Это один из краеугольных факторов для оценки риска, проверки качества ссуды, оценки рисков выдачи ипотеки и перекрестных продаж нескольких финансовых продуктов, таких как страхование.
Идентификация канала транзакции
Банки получают большое преимущество, понимая, какие из их клиентов снимают наличными всю сумму, доступную в день выплаты жалованья, а какие предпочитают хранить свои деньги на кредитной или дебетовой карте. Очевидно, что к последним клиентам можно обратиться с предложениями инвестировать в краткосрочные депозиты с высокими ставками и т. д.
Сегментация клиентов и профилирование
По завершении первоначального анализа моделей расходов клиентов и предпочтительных каналов транзакций клиентская база может быть сегментирована в соответствии с несколькими соответствующими профилями: те, кто легко тратит средства; осторожные инвесторы; те, чья цель – это быстрое погашение ссуди т.д. Знание финансовых профилей всех клиентов помогает банку оценить ожидаемые расходы и доходы в следующем месяце, а также составить подробные планы по обеспечению итоговых показателей и максимизации дохода.
Кросс-продажи продуктов
Почему бы не предложить лучшую отдачу от процентов осторожным инвесторам, чтобы стимулировать их более активно тратить? Стоит ли предоставлять краткосрочную ссуду тому, кто всеми силами пытается закрыть долги? Точный анализ финансового состояния клиентов позволяет банку более эффективно таргетировать перекрестные продажи дополнительных продуктов и лучше привлекать клиентов индивидуальными предложениями.
Управление и предотвращение мошенничества
Знание обычных моделей расходов отдельных лиц помогает поставить красный флажок, если произойдет что-то подозрительное. Если осторожный инвестор, предпочитающий платить своей картой, пытается снять все деньги со своего счета через банкомат, это может означать, что карта была украдена и использована мошенниками. Звонок из банка с запросом разрешения на такую операцию поможет легко понять, является ли это законным требованием или мошенническим действием, о котором владелец карты не знает. Анализ других типов транзакций помогает значительно снизить риск мошеннических действий.
Аналогичная процедура может быть использована для оценки риска при торговле акциями или проверке кандидата на выдачу кредита. Понимание структуры расходов и предыдущей кредитной истории клиента может помочь быстро оценить риски выдачи кредита.
Алгоритмы анализа больших данных также могут помочь в решении вопросов соответствия требованиям регулятора, аудита и отчетности, чтобы упростить административные операции и снизить управленческие издержки.
Анализ и реагирование на отзывы клиентов
Клиент может оставить отзыв после обращения в центр поддержки клиентов или через форму обратной связи, но он с гораздо большей вероятностью поделится своим мнением через социальные сети. Инструменты больших данных могут анализировать эти публичные сведения и собирать все упоминания о бренде банка, чтобы иметь возможность быстро и адекватно реагировать на них. Когда клиенты видят, что банк слышит и ценит их мнение и делает те улучшения, которые требуются, их лояльность значительно возрастает.
Big data и Российские банки
Сбербанк использует Big data для предотвращения рисков, борьбы с мошенничеством, анализа и прогнозирования возникновения очередей в отделениях банка, для оценки платежеспособности клиента, управления персоналом, расчета бонусов и премий.
Тинькофф-банк с помощью анализа больших данных анализирует потребности потенциальных и действующих клиентов, оценивает риски, планирует маркетинг и продажи.
Альфа-Банк анализирует информацию и отзывы о своей работе в социальных сетях и действия пользователей на сайте банка, а также оценивает платежеспособность клиентов с помощью Bid Data.
ВТБ использует большие данные для формирования отчета об отзывах из социальных сетей, сегментации клиентов и прогнозирования доходов, а также для прогнозирования финансовой отчетности.

- Деятельность психолога в экстремальных ситуациях
- Групповые нормы
- Работодатель как субъект трудового права
- Трудовой договор, его виды, содержание и условия заключения
- Психотип личности
- Социальные сети
- Правила личной гигиены
- How to Plan a Company Meeting
- Системная шина
- Психологическая культура психолога
- My Future Profession Is A Manager
- My future profession
Термин «Большие Данные» был впервые предложен Клиффордом Линчем, редактором журнала Nature, подготовившем 3 сентября 2008 года специальный номер журнала с темой «Как могут повлиять на будущее науки технологии, открывающие возможности работы с большими объёмами данных?», в котором были собраны материалы:
• феномена взрывного роста объёмов и многообразия обрабатываемых данных
• технологических перспектив в парадигме скачка «от количества к качеству» данных
• термин «BIG DATA» был предложен по аналогии с расхожими в деловой англоязычной среде метафорами «большая нефть», «большая руда»
Big data представляет собой значительной объем неструктуризированных данных. В отличие от статистики, сбор информации не ведется по каким-либо определенным параметрам, не имеет заранее оговоренной цели. Вы берете все доступные показатели и только потом анализируете, определяете наличие взаимосвязи и используете для повышения эффективности работы компании. Никто заранее не может предсказать, что именно сыграет решающую роль – привычки потенциальных клиентов или погодные условия в конкретной климатической зоне.
Необходимо помнить, что дешевизна сбора и хранения Big Data компенсируется необходимостью привлекать профессиональных аналитиков. К счастью, технологии постепенно вытесняют человеческий ресурс, давая возможность оперировать большими массивами информации относительно недорого.
Одной из крупнейших компаний, генерирующей информацию, является Google, не отстает от нее Facebook и Apple.
Парадигма Big Data определяет три основных типа задач.
Хранение и управление объемом данных в сотни терабайт или петабайт, которые обычные реляционные базы данных не позволяют эффективно использовать.
Организация неструктурированной информации, состоящей из текстов, изображений, видео и других типов данных.
Анализ Big Data, который ставит вопрос о способах работы с неструктурированной информацией, генерацию аналитических отчетов, а также внедрение прогностических моделей.
Одним из главных факторов, который тормозит внедрение Big Data — проектов, помимо высокой стоимости, считается проблема выбора обрабатываемых данных : то есть определение того, какие данные необходимо извлекать, хранить и анализировать, а какие – не принимать во внимание.
Основные проблемы проектов внедрения Больших Данных (BIG DATA):
Сказывается недостаток доступного пространства в системах хранения данных
Затрудняется доступ к нужным данным
Не хватает вычислительной мощности
Не хватает квалифицированного персонала
Правильно интерпретировать скрытые в массивах Больших Данных тенденции и взаимосвязи могут только подготовленные специалисты. В некоторой степени их способны заменить фильтры и распознаватели структур, но при этом качество результатов может понизится
Не удаётся учитывать скорость и частоту изменения Больших Данных
Подходы к визуализации Больших Данных отличаются сложностью и многообразием. В то же время, представление результатов в доступной для восприятия форме подчас имеет критически важное значение
Просмотр данных в реальном времени означает необходимость постоянного пересчета, что далеко не всегда приемлемо. Приходится идти на компромисс и прибегать к ретроспективному способу аналитики
Никогда нельзя знать заранее на каком временном промежутке Большие Данные представляют особую ценность и наиболее релевантны. Сбор, хранение, анализ, создание резервных копий требует немалых ресурсов
В ближайшие 8 лет количество данных в мире достигнет 35 зеттабайт, по данным исследования IDC Digital Universe, опубликованного в декабре 2012 года. По прогнозам, количество данных на планете будет удваиваться каждые два года вплоть до 2020 года. Большую часть данных, которая будет произведена в период с 2012 по 2020 годы, сгенерируют не люди, а машины в ходе взаимодействия друг с другом и другими сетями данных. Сюда относятся, например, сенсоры и интеллектуальные устройства, которые могут взаимодействовать со сторонними девайсами. Количество серверов (виртуальных и физических) во всем мире вырастет десятикратно, в первую очередь за счет расширения и создания новы [промышленных дата-центров, говорится в исследовании IDC. Тем не менее, количество обслуживающих их ИТ-специалистов увеличится не более чем в 1,5 раза. (Подробнее про рос вычислительной мощности см. рис.1.)
Рис. 1. Рост вычислительной мощности компьютерной техники (слева) на фоне трансформации парадигмы работы с данными (справа). Источник: Hilbert and López, `The world’s technological capacity to store, communicate, and compute information,`Science, 2011Global
Выделим отрасли, которые видят конкурентные преимущества от применения Big Data в ближайшие 10 – 20 лет: телеком – монетизации трафика; ритейл, банки – анализ социально-экономического поведения клиентов; власть – анализ социально-политического поведения населения, управление обществом; спецслужбы – по их направлениям деятельности; все производители товаров и услуг – оценка степени удовлетворенности клиентов товаром по отношению к конкурентным и разработка планов мероприятий по повышению степени удовлетворенности
Угрозы от применения Big Data
Конфиденциальность. Возможность потери данных или утраты контроля над ними. Здесь основную угрозу представляют собой хакерские атаки, так широко распространившиеся в современном мире. В шутку ли, с конкретной ли целью – взлом базы данных может иметь далеко идущие, а иногда фатальные последствия для бизнеса. Big Data предполагают сбор информации отовсюду – финансовые транзакции, общение в чатах, соцсетях, онлайн-конференции и т.д. Утрата такой информации либо утеря ею конфиденциальности вряд ли способна положительно отобразиться на деятельности предприятия.
Эффективность. Формирование неэффективного и бесполезного набора данных. Важно понимать, что работая с большими данными, ставку нужно делать не на накопительство информации, а на ее содержание. Вы можете получать терабайты данных каждый день, но они окажутся абсолютно неприменимыми. Не стоит увлекаться новым веянием бездумно. Большие данные требуют большого внимания и ответственности, они должны отвечать вашей бизнес-модели, иначе вы рискуете создать никому непонятный и не нужный набор цифр и букв. Или, как говорят профессионалы, «мусор на входе – мусор на выходе».
Перемены. Большие данные влекут за собой большие перемены. Иногда полученная на основе Big Data информация полностью или частично противоречит концепции компании, стилю управления, имеющимся планам. Если компания не поменяет бизнес-концепцию и не будет готова к изменениям в принципе – большие данные станут очередной бесполезной инвестицией.
Ошибки. Применяя технологии Big Data, мы не застрахованы от ошибок, и эти ошибки могут быть весьма нелепыми. Порой они задевают интересы людей и, даже, их чувства. Примеров в подтверждение тому масса. Вспомним один из них: в 2013 году сеть магазинов розничной торговли Target явно перестаралась с использованием больших данных в маркетинговых целях. В один прекрасный день в офис компании ворвался взбешенный мужчина. Он обвинил сотрудников компании в том, что те присылают его дочери скидочные купоны на памперсы, соски и прочие детские аксессуары. Мужчина злился, ведь его дочь – всего лишь школьница. Оказалось, что, используя технологии и методы обработки больших данных, сеть магазинов узнала о беременности девочки раньше, чем ее отец. Все просто – из списка регулярно покупаемых ею товаров исчезли тесты на беременность. С точностью полученной информации не поспоришь, но вот ее практическое применение оказалось не в пользу компании.
Мошенничество. Да, и это вполне возможно. При подключении системы к платному сервису сбора информации, вы надеетесь на ее достоверность (она же платная!). Иногда информация, собираемая такими ресурсами, не достоверна, она моделируется искусственно под вас, а вот проверить это практически нереально. Где вы найдете такого специалиста, который сможет дать экспертную оценку терабайтам данных? Нигде. Отсюда – большая вероятность стать жертвой «банального» обмана с целью наживы.
Подводя итог, отметим, что указанные выше риски, конечно, не перечеркивают всех достижений, но заставляют более ответственно и скрупулезно подойти к внедрению новой технологии.Сферы деятельности, в которых прогнозируется наибольший эффект от применения Big Data, представлены на рис. 2.
Рис. 2. Сферы деятельности с наиболее ощутимым прогнозируемым эффектом от применения больших данных.
Но в современных условиях предприятиям нужно обрабатывать большие объемы неструктурированных данных различных типов (рис. 3), а для этой работы прежние методы не совсем подходят.
Рис. 3. Превалирующие типы информации для разных сфер деятельности
Ожидаемый эффект от внедрения Big Data может варьироваться в зависимости от типа деятельности и реализуемой политики конкретного предприятия (рис. 4).
Рис. 4. Зависимость ожидаемого эффекта внедрения Big Data от сферы деятельности и направления политики компании
Рассмотрим способы нейтрализации рисков:
1. Риск конфиденциальности
Снизить опасность разглашения данных призвана система обеспечения безопасности. В связи с риском конфиденциальности стоит отметить особый статус сервисов хранения и обработки данных, которые предоставляются сторонними компаниями («облака сторонних лиц»). Указанный риск здесь выше и непосредственно неподконтролен. Остается доверять порядочности таких поставщиков услуг и включать в контракты условия о компенсации разглашения данных третьим лицам.
2. Риск потери данных
Существенным риском для больших данных является их утрата (частичная или полная). Причины могут быть различны: от активности злоумышленников, до чрезвычайной ситуации. Единственный способ защитится – это резервирование данных. Очевидно однократное резервирование. Если оценка риска велика и сильно влияет на бизнес, то рекомендованы двукратное и трехкратное резервирование. Одним из способов снижения рисков потери данных из-за ошибочных действий специалистов и пользователей – это предоставление рабочих копий данных (реплики полные или по запросам).
3. Риск переполнения хранилища
Неоптимальная система сбора и хранения больших данных в конечном итоге приведет к переполнению хранилища и утрате вновь получаемых данных при отсутствии места для физического их размещения. Особенность такой утраты данных – это потеря более актуальных «свежих» данных? поступающих после полного заполнения свободных объемов хранилища. Помогает тщательное планирование получения данных, умение оценивать их объемы и формировать хранилища, которые имеют адекватные емкости носителей для хранения.
4. Риск ошибок больших данных
Несколько примитивнейших ошибок (или даже одна) могут легко испортить долгую кропотливую работу. Большие данные – не исключение. А учитывая, что объемы больших данных способны достигать огромных размеров – ошибки весьма вероятны (как в содержании и структуре данных, так и в инструментах работы с ними).
Для снижения риска ошибок больших данных необходимо:
Проводить периодические ревизии данных (автоматизированные и выборочные);
Контролировать ключевые параметры данных;
Вести журнал выявленных ошибок и их устранения;
Разрабатывать инструменты и алгоритмы устранения или нивелирования ошибок и некорректных состояний данных;
Оценивать результативность инструментов;
Проводить независимую оценку и экспертизу;
Применять специальные средства тестирования данных и инструментов, которые разрабатываются самостоятельно;
Использовать инструменты последовательно, подконтрольно и пошагово с постоянным контролем обрабатываемых данных в целом или по выборкам.
Подводя итог попытаемся сформулировать с каким из топ-12 перспективных рынков для открытия бизнеса Big data будет взаимодействовать. На мой взгляд, это мобильные платежи технологии и приложения для использования смартфона в качестве средства расчетов, с помощью Big data их можно обрабатывать и определять, например на что люди тратят деньги в определенный период времени для примера после обеда. Данная взаимное перепрлетение двух технологии успешно реализуется во многом, с этим и связано внедрение технологии бесконтактной оплаты через мобильные телефоны системы Apple pay, Samsung pay они позволяют компаниям понимать на что владельцы телефонов тратят деньги, фактически это доступ к «большим данным», который был осуществлен через систему мобильных платежей.
МИНИСТЕРСТВО
ОБРАЗОВАНИЯ И НАУКИ РОССИЙСКОЙ
ФЕДЕРАЦИИФЕДЕРАЛЬНОЕ ГОСУДАРСТВЕННОЕ
АВТОНОМНОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ
ВЫСШЕГО ОБРАЗОВАНИЯ
«Национальный
исследовательский университет ИТМО»
Факультет систем
управления и робототехники
Основы проектирования
киберфизических систем.
Реферат.
Большие
данные.
Выполнил
студент группы
№
Преподаватель:
Санкт-Петербург
2019
Оглавление
Аннотация 3
Ключевые
слова 3
Введение 4
Что
такое «большие данные»? 5
Причины
использования больших данных 6
Источники
больших данных 6
Используемые
технологии 6
Сферы
применения 8
Заключение 9
Список
литературы 10
Аннотация.
Реферат:
«Большие данные»
Автор:
В
реферате рассматривается тема больших
данных, а именно: что это такое, какие
используются технологии, где применяются.
Ключевые
слова:
Большие
данные, Big
Data,
технологии больших данных, источники
больших данных,
Data
Storage, Data
Mining,
Data
Analytics,
Data
Visualization.
Введение.
Big
Data — это часть Data Science — это многогранная
дисциплина, которая охватывает машинное
обучение, статистику и связанные с нею
разделы математики и при этом дает нам
возможность для анализа данных и
извлечения из них пользы.
Cегодня
Big Data — это большой бизнес. Информация
все больше управляет нашей жизнью, и
получение выгод из нее стало центральным
моментом в работе почти любой организации.
В связи с этим растет потребность в
эффективном использовании и монетизации
этих данных
Цель
работы: ознакомиться с понятием Big Data.
Что
такое «большие данные»?
Простое
определение.
Из
названия можно предположить, что термин
«большие данные» относится просто к
управлению и анализу больших объемов
данных. Термин «большие данные» относится
к наборам данных, размер которых
превосходит возможности типичных баз
данных (БД) по занесению, хранению,
управлению и анализу информации. И
мировые репозитории данных, безусловно,
продолжают расти.
Более
сложное определение.
Тем
не менее, большие данные предполагают
нечто большее, чем просто анализ огромных
объемов информации. Проблема не в том,
что организации создают огромные объемы
данных, а в том, что бóльшая их часть
представлена в формате, плохо
соответствующем традиционному
структурированному формату БД, — это
веб-журналы, видеозаписи, текстовые
документы, машинный код или, например,
геопространственные данные. Всё это
хранится во множестве разнообразных
хранилищ, иногда даже за пределами
организации. В результате корпорации
могут иметь доступ к огромному объему
своих данных и не иметь необходимых
инструментов, чтобы установить взаимосвязи
между этими данными и сделать на их
основе значимые выводы. Добавьте сюда
то обстоятельство, что данные сейчас
обновляются все чаще и чаще, и вы получите
ситуацию, в которой традиционные методы
анализа информации не могут угнаться
за огромными объемами постоянно
обновляемых данных, что в итоге и
открывает дорогу технологиям больших
данных.
Наилучшее
определение.
В
сущности, понятие больших данных
подразумевает работу с информацией
огромного объема и разнообразного
состава, весьма часто обновляемой и
находящейся в разных источниках в целях
увеличения эффективности работы,
создания новых продуктов и повышения
конкурентоспособности.
Большие
данные имеют набор признаков трех «V»,
что означает Volume объем данных, Velocity –
необходимость обрабатывать информацию
с большой скоростью и Variety — многообразие
и часто недостаточную структурированность
данных. Однако с развитием технологий
появились и другие признаки, такие как:
veracity — достоверность, использовалась в
рекламных материалах IBM, viability
— жизнеспособность, и value – ценность,
variability — переменчивость и visualization.
Причины
использования больших данных.
Парадигма
Big Data определяет три основных типа задач:
-
Хранение
и управление объемом данных в сотни
терабайт или петабайт, которые обычные
реляционные базы данных не позволяют
эффективно использовать. -
Организация
неструктурированной информации,
состоящей из текстов, изображений,
видео и других типов данных. -
Анализ
Big Data, который ставит вопрос о способах
работы с неструктурированной информацией,
генерацию аналитических отчетов, а
также внедрение прогностических
моделей.
Источники
больших данных.
Обычно
большие данные поступают из трёх
источников:
-
Интернет
(соцсети, форумы, блоги, СМИ и другие
сайты); -
Корпоративные
архивы документов; -
Показания
датчиков, приборов и других устройств
Используемые
технологии.
Технологии
больших данных делятся на 4 раздела,
которые классифицируются следующим
образом:
-
Data
Storage; -
Data
Mining; -
Data
Analytics; -
Data
Visualization.
Соседние файлы в папке 1
- #
- #
Почему все вокруг говорят про большие данные? Какие именно данные считаются большими? Где их искать, зачем они нужны, как на них заработать? Объясняем простыми словами вместе с экспертом SkillFactory — ведущим автором курса по машинному обучению, старшим аналитиком в «КиноПоиске» Александром Кондрашкиным.
Что такое Big Data
Big Data (большие данные) — огромные наборы разнообразных данных. Огромные, потому что их объемы такие, что простой компьютер не справится с их обработкой, а разнообразные — потому что эти данные разного формата, неструктурированные и содержат ошибки. Большие данные быстро накапливаются и используются для разных целей.
Big Data — это не обычная база данных, даже если она очень большая. Вот отличия:
Объем информации в мире увеличивается ежесекундно, и то, что считали большими данными десятилетие назад, теперь умещается на жесткий диск домашнего компьютера.

60 лет назад жесткий диск на 5 мегабайт был в два раза больше холодильника и весил около тонны. Современный жесткий диск в любом компьютере вмещает до полутора десятков терабайт (1 терабайт равен 1 млн мегабайт) и по размерам меньше обычной книги.
В 2021 году большие данные измеряют в петабайтах. Один петабайт равен миллиону гигабайт. Трехчасовой фильм в формате 4K «весит» 60‒90 гигабайт, а весь YouTube — 5 петабайт или 67 тысяч таких фильмов. 1 млн петабайт — это 1 зеттабайт.
Как работает технология Big Data?
Источники сбора больших данных делятся на три типа:
- социальные;
- машинные;
- транзакционные.
Все, что человек делает в сети, — источник социальных больших данных. Каждую секунду пользователи загружают в Инстаграм* 1 тыс. фото и отправляют более 3 млн электронных писем. Ежесекундный личный вклад каждого человека — в среднем 1,7 мегабайта.
Другие примеры социальных источников Big Data — статистики стран и городов, данные о перемещениях людей, регистрации смертей и рождений и медицинские записи.
Большие данные также генерируются машинами, датчиками и «интернетом вещей». Информацию получают от смартфонов, умных колонок, лампочек и систем умного дома, видеокамер на улицах, метеоспутников.
Транзакционные данные возникают при покупках, переводах денег, поставках товаров и операциях с банкоматами.
Как обрабатывают большие данные?
Массивы Big Data настолько большие, что простой Excel с ними не справится. Поэтому для работы с ними используют специальное ПО.
Его называют «горизонтально масштабируемым», потому что оно распределяет задачи между несколькими компьютерами, одновременно обрабатывающими информацию. Чем больше машин задействовано в работе, тем выше производительность процесса.
Такое ПО основано на MapReduce, модели параллельных вычислений. Модель работает так:
- сначала данные фильтруются по условиям, которые задает исследователь, сортируются и распределяются между отдельными компьютерами (узлами);
- затем узлы параллельно рассчитывают свои блоки данных и передают результат вычислений на следующую итерацию.
MapReduce — не конкретная программа, а скорее алгоритм, с помощью которого можно решить большинство задач обработки больших данных.
Примеры ПО, которое основывается на MapReduce:
- Hadoop — набор программ с открытым исходным кодом для хранения файлов, планирования и совместной работы с данными. Система разработана так, чтобы при сбое на одном узле нагрузка сразу перераспределялась на другие, не прерывая вычисления.
- Apache Spark — набор библиотек, которые позволяют выполнять вычисления в оперативной памяти и многократно обращаться к результатам расчетов. Его применяют для решения широкого круга задач, от простой обработки и фильтрации данных до машинного обучения.
Специалисты по большим данным используют оба инструмента: Hadoop для создания инфраструктуры данных и Spark для обработки потоковой информации в реальном времени.
Читайте также: Отзыв о профессии Data Scientist, рассказ о карьерном пути и советы для новичков
Где применяется аналитика больших данных?
Большие данные нужны в маркетинге, перевозках, автомобилестроении, здравоохранении, науке, сельском хозяйстве и других сферах, в которых можно собрать и обработать нужные массивы информации.
Бизнесу большие данные нужны, чтобы:
- Оптимизировать процессы — например, крупные банки используют большие данные, чтобы обучать чат-бота — программу, которая заменит живого сотрудника по простым вопросам и при необходимости переключит на специалиста.
- Делать прогнозы — анализируя большие данные о продажах, компании могут предсказать поведение клиентов и покупательский спрос на товары в зависимости от времени года или ситуации в мире.
- Строить модели — с помощью анализа данных о прибыли и издержках компания может построить модель для прогнозирования выручки.
Анализ больших данных позволяет не только систематизировать информацию, но и находить неочевидные причинно-следственные связи.
Продажи товаров
Онлайн-маркетплейс Amazon запустил систему рекомендаций товаров, работающую на машинном обучении. Она учитывает не только поведение и предыдущие покупки пользователя, но и время года, ближайшие праздники и остальные факторы. После того как эта система заработала, рекомендации начали генерировать 35% всех продаж сервиса.
В супермаркетах «Лента» с помощью больших данных анализируют информацию о покупках и предлагают персонализированные скидки на товары. К примеру, говорят в компании, система по данным о покупках может понять, что клиент изменил подход к питанию, и начнет предлагать ему подходящие продукты.
Американская сеть Kroger использует большие данные для персонализации скидочных купонов, которые получают покупатели по электронной почте. После того как их сделали индивидуальными, подходящими конкретным покупателям, доля покупок только по ним выросла с 3,7 до 70%.
Читайте также: Чем занимается дата-инженер в X5 retail Group?
Найм сотрудников
Крупные компании, в том числе российские, стали прибегать к помощи роботов-рекрутеров, чтобы на начальном этапе поиска сотрудника отсеять тех, кто не заинтересован в вакансии или не подходит под нее. Так, компания Stafory разработала робота Веру, которая сортирует резюме, делает первичный обзвон и выделяет заинтересованных кандидатов. PepsiCo заполнила 10% нужных вакансий только с помощью робота.
Банки
Банки активно используют большие данные. Например, они помогают защищать клиентов от мошенников. Именно с помощью этих технологий обнаруживают аномалии в поведении пользователя, нетипичные для него покупки или переводы. Уже в 2017 году Visa с помощью анализа данных ежегодно предотвращала мошенничества на $2 млрд.
Автомобилестроение
В 2020 году у автоконцерна Toyota возникла проблема: нужно было понять причину большого числа аварий по вине водителей, перепутавших педали газа и тормоза. Компания собрала данные со своих автомобилей, подключенных к интернету, и на их основе определила, как именно люди нажимают на педали.
Оказалось, что сила и скорость давления различаются в зависимости от того, хочет человек затормозить или ускориться. Теперь компания разрабатывает систему, которая будет определять манеру давления на педали во время движения и сбросит скорость автомобиля, если водитель давит на педаль газа, но делает это так, будто хочет затормозить.
Медицина
Американские ученые научились с помощью больших данных определять, как распространяется депрессия. Исследователь Мунмун Де Чаудхури и ее коллеги загрузили в прогностическую модель сообщения из Twitter, Фейсбук* с геометками. Сообщения отбирали по словам, которые могут указывать на депрессивное и подавленное состояние. Расчеты совпали с официальными данными.
Госструктуры
Большие данные просто необходимы госструктурам. С их помощью ведется не только статистика, но и слежка за гражданами. Подобные системы есть во многих странах: известен сервис PRISM, которыми пользуются ФБР и ЦРУ для сбора персональных данных из соцсетей и продуктов Microsoft, Google и Apple. В России информацию о пользователях и телефонных звонках собирает система СОРМ.
Маркетинг
Социальные большие данные помогают группировать пользователей по интересам и персонализировать для них рекламу. Людей ранжируют по возрасту, полу, интересам и месту проживания. Те, кто живут в одном регионе, бывают в одних и тех же местах, смотрят видео и читают статьи на похожие темы, скорее всего, заинтересуются одними и теми же товарами.
При этом регулярно происходят скандалы, связанные с использованием больших данных в маркетинге. Так, в 2018 году стриминговую платформу Netflix обвинили в расизме из-за того, что она показывает пользователям разные постеры фильмов и сериалов в зависимости от их пола и национальности.
Читайте также: Чем занимается дата-сайентист в «ИТ Магнит»?
Медиа
С помощью анализа больших данных в медиа измеряют аудиторию. В этом случае Big Data может даже повлиять на политику редакции. Так, издание Huffington Post использует систему, которая в режиме реального времени показывает статистику посещений, комментариев и других действий пользователей, а также готовит аналитические отчеты.
Система в Huffington Post оценивает, насколько эффективно заголовки привлекают внимание читателя, разрабатывает методы доставки контента определенным категориям пользователей. Например, выяснилось, что родители чаще читают статьи со смартфона и поздно вечером в будни, после того как уложили детей спать, а по выходным они обычно заняты, — в итоге контент для родителей публикуется на сайте в удобное для них время.
Логистика
Использование больших данных помогает оптимизировать перевозки, сделать доставку быстрее и дешевле. В компании DHL работа с большими данными коснулась так называемой проблемы последней мили, когда необходимость проехать через дворы и найти парковку перед тем, как отдать заказ, съедает в общей сложности 28% от стоимости доставки. В компании стали анализировать «последние мили» с помощью информации с GPS и данных о дорожной обстановке. В результате удалось сократить затраты на топливо и время доставки груза.
Внутри компании большие данные помогают отслеживать качество работы сотрудников, соблюдение контрольных сроков, правильность их действий. Для анализа используют машинные данные, например со сканеров посылок в отделениях, и социальные — отзывы посетителей отделения в приложении, на сайтах и в соцсетях.
Читайте также: Чем занимается тимлид-аналитик в сервисе срочной доставки Gett Delivery?
Обработка фото
До 2016 года не было технологии нейросетей на мобильных устройствах, это даже считали невозможным. Прорыв в этой области (в том числе благодаря российскому стартапу Prisma) позволяет нам сегодня пользоваться огромным количеством фильтров, стилей и разных эффектов на фотографиях и видео.
Аренда недвижимости
Сервис Airbnb с помощью Big Data изменил поведение пользователей. Однажды выяснилось, что посетители сайта по аренде недвижимости из Азии слишком быстро его покидают и не возвращаются. Оказалось, что они переходят с главной страницы на «Места поблизости» и уходят смотреть фотографии без дальнейшего бронирования.
Компания детально проанализировала поведение пользователей и заменила ссылки в разделе «Места поблизости» на самые популярные направления для путешествий в азиатских странах. В итоге конверсия в бронирования из этой части планеты выросла на 10%.
*деятельность компании Meta Platforms Inc., которой принадлежит Инстаграм / Фейсбук, запрещена на территории РФ в части реализации данной (-ых) социальной (-ых) сети (-ей) на основании осуществления ею экстремистской деятельности
Кто работает с большими данными?
Три основные профессии в больших данных: дата-инженер, дата-сайентист, аналитик данных.
Дата-сайентисты специализируются на анализе Big Data. Они ищут закономерности, строят модели и на их основе прогнозируют будущие события.
Например, исследователь больших данных может использовать статистику по снятиям денег в банкоматах, чтобы разработать математическую модель для предсказания спроса на наличные. Эта система подскажет инкассаторам, сколько денег и когда привезти в конкретный банкомат.
Чтобы освоить эту профессию, необходимо понимание основ математического анализа и знание языков программирования, например Python или R, а также умение работать с SQL-базами данных.
Аналитик данных использует тот же набор инструментов, что и дата-сайентист, но для других целей. Его задачи — делать описательный анализ, интерпретировать и представлять данные в удобной для восприятия форме. Он обрабатывает данные и выдает результат, составляя аналитические отчеты, статистику и прогнозы.
С Big Data также работают и другие специалисты, для которых это не основная сфера работы:
- дизайнеры интерфейсов, анализирующие данные поведенческих исследований для создания пользовательских интерфейсов;
- NLP-инженеры, которые разрабатывают программы для чат-ботов и автоматизации колл-центров, анализируя естественный язык;
- маркетологи-аналитики, которые исследуют массив данных для выстраивания маркетинговой политики и персонализации рекламы;
- инженеры и программисты на предприятиях, занимающиеся обработкой данных.
Дата-инженер занимается технической стороной вопроса и первый работает с информацией: организует ее сбор, хранение и первоначальную обработку.
Дата-инженеры помогают исследователям, создавая ПО и алгоритмы для автоматизации задач. Без таких инструментов большие данные были бы бесполезны, так как их объемы невозможно обработать. Для этой профессии важно знание Python и SQL, уметь работать с фреймворками, например со Spark.
Александр Кондрашкин о других профессиях, в которых может понадобиться Big Data: «Где-то может и product-менеджер сам сходить в Hadoop-кластер и посчитать что-то несложное, если обладает такими навыками. Наверняка есть множество backend-разработчиков и DevOps-инженеров, которые настраивают хранение и сбор данных от пользователей».
Востребованность больших данных и специалистов по ним
Востребованность больших данных растет: по исследованиям 2020 года, даже при пессимистичном сценарии объем рынка Big Data в России к 2024 году вырастет с 45 млрд до 65 млрд рублей, а при хорошем развитии событий — до 230 млрд.
Компании все чаще прибегают к анализу больших данных, так как те, кто этого не делает, замечают упущенную выгоду: The Bell приводит пример корпорации Caterpillar. В 2014 году ее дистрибьюторы ежегодно упускали от $9 до $18 млрд прибыли только из-за того, что не внедряли технологии обработки Big Data. Теперь 3,5 млн единиц техники компании оборудованы датчиками, которые собирают информацию о ее состоянии и степени износа ключевых деталей, что позволяет лучше управлять затратами на техобслуживание.
Более трети вакансий для специалистов по анализу данных (38%) приходится на IT-компании, финансовый сектор (29%) и сферу услуг для бизнеса (9%). В сфере машинного обучения IT-компании публикуют 55% вакансий на рынке, 10% приходит из финансового сектора и 9% — из сферы услуг.
Как начать работать с большими данными?
Проще будет начать, если у вас уже есть понимание алгоритмов и хорошее знание математики, но это не обязательно. Например, Оксана Дереза была филологом и для нее главной трудностью в Data Science оказалось вспомнить математику и разобраться в алгоритмах, но она много занималась и теперь анализирует данные в исследовательском институте.
Еще несколько историй людей, которые успешно освоили data-профессию.
Виктор Коваценко: Как я бросил финансы, изучил Data Science и уехал работать в Берлин
Иван Алешин: Я был геологом и ездил в тайгу, а теперь работаю дата-сайентистом в зарубежной компании
Леонид Яковлев: Как я бросил нелюбимую работу и стал аналитиком данных
Если у вас нет математических знаний, на курсе SkillFactory «Data Science с нуля» вы получите достаточную подготовку, чтобы работать с большими данными. За год вы научитесь получать данные из веб-источников или по API, визуализировать данные с помощью Pandas и Matplotlib, применять методы математического анализа, линейной алгебры, статистики и теории вероятности для обработки данных и многое другое.
Чтобы стать аналитиком данных, вам пригодится знание Python и SQL — эти навыки очень популярны в вакансиях компаний по поиску соответствующей позиции. На курсе «Аналитик данных» вы получите базу знаний основных инструментов аналитики (от Google-таблиц до Python и Power BI) и закрепите их на тренажерах.
Важно определиться со сферой, в которой вы хотите работать. Студентка SkillFactory Екатерина Карпова, рассказывает, что после обучения ей была важна не должность, а сфера (финтех), поэтому она сначала устроилась консультантом в банк «Тинькофф», а теперь работает там аналитиком.
Смартфоны предлагают нам загрузить все данные в облако, а большие компании вроде Google и «Яндекса» — воспользоваться своими экосистемами. Проще говоря, мы живем в эпоху Big Data. Но что это значит на самом деле?
1
Что такое Big Data?
Big Data или большие данные — это структурированные или неструктурированные массивы данных большого объема. Их обрабатывают при помощи специальных автоматизированных инструментов, чтобы использовать для статистики, анализа, прогнозов и принятия решений.
Сам термин «большие данные» предложил редактор журнала Nature Клиффорд Линч в спецвыпуске 2008 года [1]. Он говорил о взрывном росте объемов информации в мире. К большим данным Линч отнес любые массивы неоднородных данных более 150 Гб в сутки, однако единого критерия до сих пор не существует.
«Лиза Алерт» использует Big Data, чтобы находить пропавших людей
До 2011 года анализом больших данных занимались только в рамках научных и статистических исследований. Но к началу 2012-го объемы данных выросли до огромных масштабов, и возникла потребность в их систематизации и практическом применении.
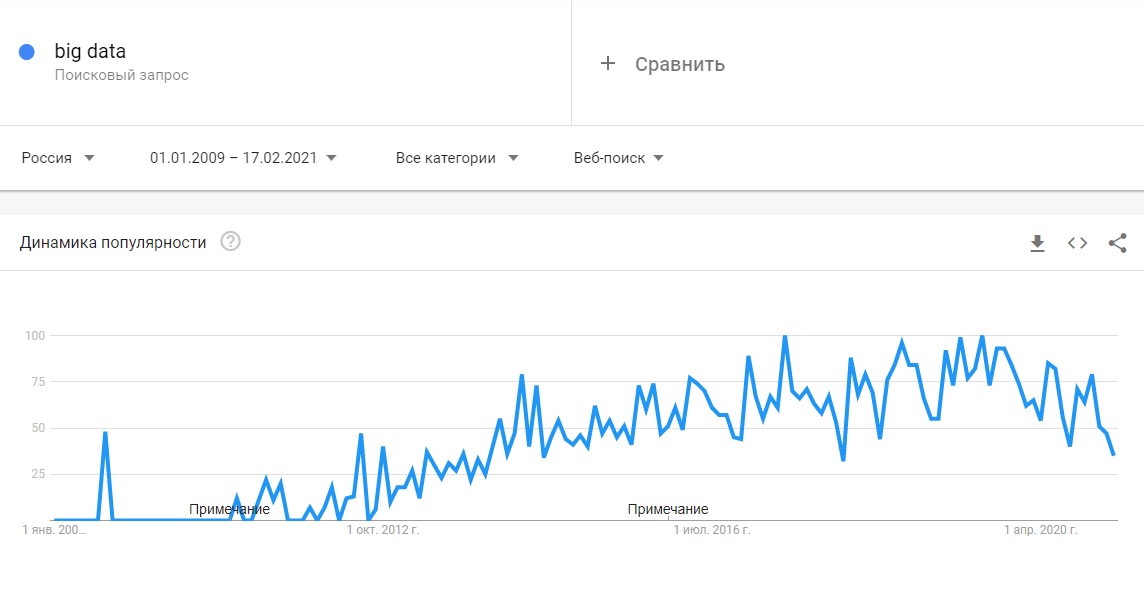
Всплеск интереса к большим данным в Google Trends
С 2014 на Big Data обратили внимание ведущие мировые вузы, где обучают прикладным инженерным и IT-специальностям. Затем к сбору и анализу подключились IT-корпорации — такие, как Microsoft, IBM, Oracle, EMC, а затем и Google, Apple, Facebook (с 21 марта 2022 года соцсеть запрещена в России решением суда) и Amazon. Сегодня большие данные используют крупные компании во всех отраслях, а также — госорганы. Подробнее об этом — в материале «Кто и зачем собирает большие данные?»
2
Какие есть характеристики Big Data?
Компания Meta Group предложила основные характеристики больших данных [2]:
- Volume — объем данных: от 150 Гб в сутки;
- Velocity — скорость накопления и обработки массивов данных. Большие данные обновляются регулярно, поэтому необходимы интеллектуальные технологии для их обработки в режиме онлайн;
- Variety — разнообразие типов данных. Данные могут быть структурированными, неструктурированными или структурированными частично. Например, в соцсетях поток данных не структурирован: это могут быть текстовые посты, фото или видео.
Сегодня к этим трем добавляют еще три признака [3]:
- Veracity — достоверность как самого набора данных, так и результатов его анализа;
- Variability — изменчивость. У потоков данных бывают свои пики и спады под влиянием сезонов или социальных явлений. Чем нестабильнее и изменчивее поток данных, тем сложнее его анализировать;
- Value — ценность или значимость. Как и любая информация, большие данные могут быть простыми или сложными для восприятия и анализа. Пример простых данных — это посты в соцсетях, сложных — банковские транзакции.
3
Как работает Big Data: как собирают и хранят большие данные?
Большие данные необходимы, чтобы проанализировать все значимые факторы и принять правильное решение. С помощью Big Data строят модели-симуляции, чтобы протестировать то или иное решение, идею, продукт.
Главные источники больших данных:
- интернет вещей (IoT) и подключенные к нему устройства;
- соцсети, блоги и СМИ;
- данные компаний: транзакции, заказы товаров и услуг, поездки на такси и каршеринге, профили клиентов;
- показания приборов: метеорологические станции, измерители состава воздуха и водоемов, данные со спутников;
- статистика городов и государств: данные о перемещениях, рождаемости и смертности;
- медицинские данные: анализы, заболевания, диагностические снимки.
С 2007 года в распоряжении ФБР и ЦРУ появилась PRISM — один из самых продвинутых сервисов, который собирает персональные данные обо всех пользователях соцсетей, а также сервисов Microsoft, Google, Apple, Yahoo и даже записи телефонных разговоров.
Современные вычислительные системы обеспечивают мгновенный доступ к массивам больших данных. Для их хранения используют специальные дата-центры с самыми мощными серверами.
Как выглядит современный дата-центр
Помимо традиционных, физических серверов используют облачные хранилища, «озера данных» (data lake — хранилища большого объема неструктурированных данных из одного источника) и Hadoop — фреймворк, состоящий из набора утилит для разработки и выполнения программ распределенных вычислений. Для работы с Big Data применяют передовые методы интеграции и управления, а также подготовки данных для аналитики.
4
Big Data Analytics — как анализируют большие данные?
Благодаря высокопроизводительным технологиям — таким, как грид-вычисления или аналитика в оперативной памяти, компании могут использовать любые объемы больших данных для анализа. Иногда Big Data сначала структурируют, отбирая только те, что нужны для анализа. Все чаще большие данные применяют для задач в рамках расширенной аналитики, включая искусственный интеллект.
Выделяют четыре основных метода анализа Big Data [4]:
1. Описательная аналитика (descriptive analytics) — самая распространенная. Она отвечает на вопрос «Что произошло?», анализирует данные, поступающие в реальном времени, и исторические данные. Главная цель — выяснить причины и закономерности успехов или неудач в той или иной сфере, чтобы использовать эти данные для наиболее эффективных моделей. Для описательной аналитики используют базовые математические функции. Типичный пример — социологические исследования или данные веб-статистики, которые компания получает через Google Analytics.
Антон Мироненков, управляющий директор «X5 Технологии»:
«Есть два больших класса моделей для принятия решений по ценообразованию. Первый отталкивается от рыночных цен на тот или иной товар. Данные о ценниках в других магазинах собираются, анализируются и на их основе по определенным правилам устанавливаются собственные цены.
Второй класс моделей связан с выстраиванием кривой спроса, которая отражает объемы продаж в зависимости от цены. Это более аналитическая история. В онлайне такой механизм применяется очень широко, и мы переносим эту технологию из онлайна в офлайн».
2. Прогнозная или предикативная аналитика (predictive analytics) — помогает спрогнозировать наиболее вероятное развитие событий на основе имеющихся данных. Для этого используют готовые шаблоны на основе каких-либо объектов или явлений с аналогичным набором характеристик. С помощью предикативной (или предиктивной, прогнозной) аналитики можно, например, просчитать обвал или изменение цен на фондовом рынке. Или оценить возможности потенциального заемщика по выплате кредита.
3. Предписательная аналитика (prescriptive analytics) — следующий уровень по сравнению с прогнозной. С помощью Big Data и современных технологий можно выявить проблемные точки в бизнесе или любой другой деятельности и рассчитать, при каком сценарии их можно избежать их в будущем.
Сеть медицинских центров Aurora Health Care ежегодно экономит $6 млн за счет предписывающей аналитики: ей удалось снизить число повторных госпитализаций на 10% [5].
4. Диагностическая аналитика (diagnostic analytics) — использует данные, чтобы проанализировать причины произошедшего. Это помогает выявлять аномалии и случайные связи между событиями и действиями.
Например, Amazon анализирует данные о продажах и валовой прибыли для различных продуктов, чтобы выяснить, почему они принесли меньше дохода, чем ожидалось.
Данные обрабатывают и анализируют с помощью различных инструментов и технологий [6] [7]:
- Cпециальное ПО: NoSQL, MapReduce, Hadoop, R;
- Data mining — извлечение из массивов ранее неизвестных данных с помощью большого набора техник;
- ИИ и нейросети — для построения моделей на основе Big Data, включая распознавание текста и изображений. Например, оператор лотерей «Столото» сделал большие данные основой своей стратегии в рамках Data-driven Organization. С помощью Big Data и искусственного интеллекта компания анализирует клиентский опыт и предлагает персонифицированные продукты и сервисы;
- Визуализация аналитических данных — анимированные модели или графики, созданные на основе больших данных.
Примеры визуализации данных (data-driven animation)
Как отметил в подкасте РБК Трендов менеджер по развитию IoT «Яндекс.Облака» Александр Сурков, разработчики придерживаются двух критериев сбора информации:
- Обезличивание данных делает персональную информацию пользователей в какой-то степени недоступной;
- Агрегированность данных позволяет оперировать лишь со средними показателями.
Чтобы обрабатывать большие массивы данных в режиме онлайн используют суперкомпьютеры: их мощность и вычислительные возможности многократно превосходят обычные. Подробнее — в материале «Как устроены суперкомпьютеры и что они умеют».
Big Data и Data Science — в чем разница?
Data Science или наука о данных — это сфера деятельности, которая подразумевает сбор, обработку и анализ данных, — структурированных и неструктурированных, не только больших. В ней используют методы математического и статистического анализа, а также программные решения. Data Science работает, в том числе, и с Big Data, но ее главная цель — найти в данных что-то ценное, чтобы использовать это для конкретных задач.
5
В каких отраслях уже используют Big Data?
- Государственное управление. Изучение и анализ больших данных помогает правительствам принимать решения в таких областях, как здравоохранение, занятость населения, экономическое регулирование, борьба с преступностью и обеспечение безопасности, реагирование на чрезвычайные ситуации;
- Промышленность. Внедрение инструментов Big Data помогает повысить прозрачность промышленных процессов и внедрять «предиктивное производство», позволяющее более точно прогнозировать спрос на продукцию и, соответственно, планировать расходование ресурсов;
- Медицина. Огромное количество данных, собираемых медицинскими учреждениями и различными электронными приспособлениями (фитнес-браслетами и т.п.) открывает принципиально новые возможности перед индустрией здравоохранения. Большие данные помогают находить новые лекарства, точнее ставить диагнозы, подбирать эффективное лечение, бороться с пандемий;
- Ретейл. Развитие сетевой и электронной торговли невозможно представить без основанных на Big Data решениях — так магазины персонализируют ассортимент и доставку;
- Интернет вещей. Big Data и интернет вещей неразрывно связаны между собой. Промышленные и бытовые приборы, подключенные к интернету вещей, собирают огромное количество данных, на основе анализа которых впоследствии регулируется работа этих приборов;
- Рынок недвижимости. Девелоперы используют технологии Big Data, чтобы собрать и проанализировать весь массив информации, а затем выдать пользователю наиболее интересные для него варианты. Уже сейчас будущий покупатель может посмотреть понравившийся дом без продавца;
- Спорт. С помощью больших данных футбольные клубы отбирают самых перспективных игроков и разрабатывают эффективную стратегию для каждого противника.
Выпуск «Индустрии 4.0» о том, как используют Big Data в футболе
- Сельское хозяйство.
«IoT-решение из области так называемого точного земледелия — это когда специальные метеостанции, которые стоят в полях, с помощью сенсоров собирают данные (температура, влажность) и с помощью передающих радио-GSM-модулей отправляют их на IoT-платформу. На ней посредством алгоритмов big data происходит обработка собранной с сенсоров информации и строится высокоточный почасовой прогноз погоды. Клиент видит его в интерфейсе на компьютере, планшете или смартфоне и может оперативно принимать решения», — прокомментировали в «МегаФоне».
Подробнее — в материале «Умные» комбайны и дроны-геологи: как цифровизация меняет экономику».
6
Big Data в России и мире
По данным компании IBS [8], в 2012 году объем хранящихся в мире цифровых данных вырос на 50%: с 1,8 до 2,7 Збайт (2,7 трлн Гбайт). В 2015-м в мире каждые десять минут генерировалось столько же данных, сколько за весь 2003 год.
По данным компании NetApp, к 2003 году в мире накопилось 5 Эбайтов данных (1 Эбайт = 1 млрд Гбайт). В 2015-м — более 6,5 Збайта, причем тогда большие данные использовали лишь 17% компаний по всему миру [9]. Большую часть данных будут генерировать сами компании, а не их клиенты. При этом обычный пользователь будет коммуницировать с различными устройствами, которые генерируют данные, около 4 800 раз в день.
Первыми Big Data еще пять лет назад начали использовать в ИТ, телекоме и банках. Именно в этих сферах скапливается большой объем данных о транзакциях, геолокации, поисковых запросах и профилях в Сети. В 2019 году прибыль от использования больших данных оценивались в $189 млрд [10] — на 12% больше, чем в 2018-м, при этом к 2022 году она ежегодно будет удваиваться.
Сейчас в США с большими данными работает более 55% компаний [11], в Европе и Азии — около 53%. Только за последние пять лет распространение Big Data в бизнесе выросло в три раза.
Как большие данные помогают онлайн-кинотеатрам подбирать персональные рекомендации
Мировыми лидерами по сбору и анализу больших данных являются США и Китай. Так, в США еще при Бараке Обаме правительство запустило шесть федеральных программ по развитию больших данных на общую сумму $200 млн. Главными потребителями Big Data считаются крупные корпорации, однако их деятельность по сбору данных ограничена в некоторых штатах — например, в Калифорнии.
В Китае действует более 200 законов и правил, касающихся защиты личной информации. С 2019 года все популярные приложения для смартфонов начали проверять и блокировать, если они собирают данные о пользователях вопреки законам. В итоге данные через местные сервисы собирает государство, и многие из них недоступны извне.
С 2018 года в Евросоюзе действует GDPR — Всеобщий регламент по защите данных. Он регулирует все, что касается сбора, хранения и использования данных онлайн-пользователей. Когда закон вступил в силу год назад, он считался самой жесткой в мире системой защиты конфиденциальности людей в Интернете.
Подробнее — в материале «Цифровые войны: как искусственный интеллект и большие данные правят миром».
В России рынок больших данных только зарождается. К примеру, сотовые операторы делятся с банками информацией о потенциальных заемщиках [12]. Среди корпораций, которые собирают и анализируют данные — «Яндекс», «Сбер», Mail.ru. Появились специальные инструменты, которые помогают бизнесу собирать и анализировать Big Data — такие, как российский сервис Ctrl2GO.
7
Big Data в бизнесе
Большие данные полезны для бизнеса в трех главных направлениях:
- Запуск продуктов и сервисов, которые точнее всего «выстрелят» по потребностям целевой аудитории;
- Анализ клиентского опыта в отношении продукта или услуги, чтобы улучшить их;
- Привлечение и удержание клиентов с помощью аналитики.
Большие данные помогают MasterCard предотвращать мошеннические операции со счетами клиентов на сумму более $3 млрд в год [13]. Они позволяют рекламодателям эффективнее распределять бюджеты и размещать рекламу, которая нацелена на самых разных потребителей.
Крупные компании — такие, как Netflix, Procter & Gamble или Coca-Cola — с помощью больших данных прогнозируют потребительский спрос. 70% решений в бизнесе и госуправлении принимается на основе геоданных. Подробнее — в материале о том, как бизнес извлекает прибыль из Big Data.
8
Каковы проблемы и перспективы Big Data?
Главные проблемы:
- Большие данные неоднородны, поэтому их сложно обрабатывать для статистических выводов. Чем больше требуется параметров для прогнозирования, тем больше ошибок накапливается при анализе;
- Для работы с большими массивами данных онлайн нужны огромные вычислительные мощности. Такие ресурсы обходятся очень дорого, и пока что доступны только большим корпорациям;
- Хранение и обработка Big Data связаны с повышенной уязвимостью для кибератак и всевозможных утечек. Яркий пример — скандалы с профилями Facebook;
- Сбор больших данных часто связан с проблемой приватности: не все хотят, чтобы каждое их действие отслеживали и передавали третьим лицам. Герои подкаста «Что изменилось» объясняют, почему конфиденциальности в Сети больше нет, и технологическим гигантам известно о нас все;
- Большие данные используют в своих целях не только корпорации, но и политики: например, чтобы повлиять на выборы.
Плюсы и перспективы:
- Большие данные помогают решать глобальные проблемы — например, бороться с пандемией, находить лекарства от рака и предотвращать экологический кризис;
- Big Data — хороший инструмент для создания умных городов и решения проблемы транспорта;
- Большие данные помогают экономить средства даже на государственном уровне: например, в Германии вернули в бюджет около €15 млрд [14], обнаружив, что часть граждан получают пособие по безработице без всяких оснований. Их вычислили с помощью транзакций.
Как Big Data и ИИ меняют наше представление о справедливости
В ближайшем будущем большие данные станут главным инструментом для принятия решений — начиная с сетевых бизнесов и заканчивая целыми государствами и международными организациями [15].
Библиографическое описание:
Коновалов, М. В. Big Data. Особенности и роль в современном бизнесе / М. В. Коновалов. — Текст : непосредственный // Технические науки: проблемы и перспективы : материалы VI Междунар. науч. конф. (г. Санкт-Петербург, июль 2018 г.). — Санкт-Петербург : Свое издательство, 2018. — С. 8-10. — URL: https://moluch.ru/conf/tech/archive/288/14418/ (дата обращения: 01.04.2023).
В статье рассматриваются основные понятия, связанные с big data, основы и принципы работы с методами и подходами больших данных. Анализируются текущие тенденции на современном рынке предоставляемых услуг и продуктов, а также в каких случаях могут применяться подобные технологии, и почему большие данные, несмотря на дороговизну, все больше набирают популярность.
Ключевые слова: big bata, большие данные, масштабируемость, транзакционная система, информационная система, анализ, программное обеспечение, БД, ИТ.
Введение
Не секрет, что на сегодняшний день объемы данных, которые требуется хранить и обрабатывать, растут в геометрической прогрессии. Например, объемы данных, которые хранятся в Интернет, увеличиваются примерно на 40 % ежегодно. Интересно, что с одной стороны, именно развитие современных информационных технологий позволяет и способствует тому, чтобы объемы сохраняемых и обрабатываемых данных постоянно росли. А с другой стороны, для работы с быстрорастущими объемами самых разнообразных видов данных требуется все больше ресурсов и более сложных программных решений. Одной из наиболее современных и быстро набирающих популярность технологий является big data. Этот термин стал применяться и быстро набирать популярность всего 8–10 лет назад. А сегодня крупнейшие мировые компании, занимающие лидирующие позиции в самых разных областях бизнес деятельности, вкладывают миллиарды долларов в развитие этого направления. В данной статье рассмотрены основные понятия, связанные с технологией big data, почему одни крупные компании готовы вкладывать огромные средства в развитие этого направления, а другие нет. Какие наиболее распространенные решения на основе big data существуют сегодня на рынке, какие есть сложности и что ждет остальной рынок ИТ с приходом новой технологии.
Понятие Big Data
Дословно big data означает большие данные. Более подробное определение можно сформулировать так. Big data — это серия подходов и методов обработки большого объема и значительного многообразия данных, которые тяжело обработать обычными способами. Целью обработки больших данных является получение новой информации. При этом данные могут быть как обработанными (структурированными), так и разрозненными (то есть неструктурированными).
Если говорить о типах данных, для которых применимы рассматриваемые методы обработки, то это может быть совершенно разная информация: документы, блоги, социальные сети, любые клиентские данные или даже информация о совершенных клиентами действиях. Также информация, поступающая от измерительных устройств и т. д. Но это все преимущественно текстовая информация. Помимо этого, обработке могут подлежать аудио и видео данные, изображения и т. д.
Но не все абсолютно данные подлежат обработке с применением технологий big data. Есть критерии, по которым можно отнести информацию и данные, пригодные к подобной обработке, т. к. не все данные могут быть пригодны для аналитики. В этих определяющих характеристиках как раз и заложено ключевое понятие больших данных. Все они умещаются в т. н. три V:
Объем (от англ. volume). Данные измеряются величиной физического объема “документа”, который подлежит анализу.
Скорость (от англ. velocity). Данные не статичны в своем развитии, а постоянно прирастают. Поэтому смысл этой характеристики не только в быстро растущих объемах данных, но и в необходимости их быстрой обработки для получения требуемых результатов.
Многообразие (от англ. variety). Данные могут быть не одноформатными. То есть могут быть разрозненными, структурированными, не структурированными или структурированными частично. И смысл заключается в том, чтобы одновременно обрабатывать различные типы данных.
Также к уже рассмотренным трем V, в разных источниках добавляют четвертую. Достоверность или правдоподобность (от англ. veracity). И даже пятую жизнеспособность или ценность (от англ. viability или value). В различных вариантах можно говорить о 7V, но для базового понимания достаточно трех.
Принципы работы big data
Исходя из определения big bata, можно сформулировать три основных принципа работы с такими данными:
Горизонтальная масштабируемость. Поскольку объем данных постоянно и стремительно растет и информации может быть сколь угодно много, то система, которая подразумевает обработку этих данных, должна быть расширяемой. К примеру, если 2 раза вырос объём данных, то должна быть возможность увеличить мощность аппаратного обеспечения в 2 раза в кластере и система продолжит работать без потерь в производительности.
Отказоустойчивость. Рассмотренный выше принцип горизонтальной масштабируемости подразумевает, что машин в кластере может быть много. Например, в компании Yahoo кластер насчитывает более 40000 машин. При этом допускается, что часть этих машин будет регулярно выходить из строя. Методы работы с большими данными должны учитывать вероятность таких сбоев и поддерживать работоспособность системы без каких-либо значимых последствий.
Локальность данных. В крупных распределённых системах, используемые данные хранятся на большом количестве машин. Но если данные находятся физически на одном сервере, а обрабатываются на другом, то ресурсы, требуемые на передачу данных, могут превысить расходы на обработку данных. Поэтому при проектировании решений на big data одним из важнейших принципов является принцип локальности данных, суть которого заключается в том, чтобы данные обрабатывались и хранились на одной и той же машине.
Особенности применения и роль в современном бизнесе
Изучая многообразие современных технологий хранения и обработки данных, возникает логичный вопрос. Для чего придуманы методы и подходы, называемые big data? Что в этом уникального, как можно использовать информацию, обработанную с помощью данных технологий и почему компании готовы вкладывать в развитие больших данных огромные средства?
Во-первых, в отличие от big data, обычные базы данных (БД), не могут хранить и обрабатывать такие огромные объемы данных (сотни и тысячи терабайт). И речь даже не об аналитике, а только лишь о хранении данных. В классическом понимании БД предназначена для быстрой обработки (хранение, изменение) относительно небольших объемов данных или для работы с большим потоком записей небольшого размера, т. е. транзакционная система. С помощью big data как раз решается эта основная задача — успешное хранение и обработка больших объемов данных.
Во-вторых, в big data структурируются разнотипные сведения, которые поступают из различных источников (изображения, фото, видео, аудио и текстовые документы) в один единый, понятный и приемлемый для дальнейшей работы вид.
В-третьих, в big data происходит формирование аналитики и построение точных прогнозов на основании полученной и обработанной информации.
Для чего это нужно и где может быть применено на практике? Для наглядности и для того, чтобы сформулировать ответ простыми словами, рассмотрим на примере типичных бизнес-задач в маркетинге. Обладая такой информацией, как:
‒ полное понимание о своей компании и бизнесе, в том числе с точки зрения статистической информации и цифр;
‒ подробные данные о конкурентах;
‒ новая и подробная информация о своих клиентах;
‒ все это позволит преуспеть в привлечении новых клиентов, значительно повысить уровень предоставляемого сервиса текущим клиентам, лучше понять рынок и своих конкурентов, а значит вырваться вперед за счет преобладания над ними.
Учитывая вышеперечисленные результаты, которых позволяет достигнуть big data, и объясняет стремление компаний, пытающихся завоевать рынок, вкладываться в эти современные методы обработки данных сегодня, чтобы получить увеличение продаж и уменьшение издержек завтра. А если более конкретно, то:
‒ увеличение дополнительных продаж и кросс продаж за счет лучшего знания предпочтений клиентов;
‒ поиск популярных товаров и причин — почему их покупают или наоборот;
‒ усовершенствование предоставляемой услуги или продукта;
‒ повышение качества обслуживания клиентов;
‒ повышение лояльности и клиентоориентированности;
‒ предупреждение мошенничества (больше актуально для банковской сферы);
‒ снижение лишних расходов.
Один из наиболее наглядных и популярных на сегодняшний день примеров, о котором можно прочитать во многих источниках сети Интернет, связан с компанией Apple, которая собирает данные о своих пользователях с помощью производимых устройств: телефон, планшет, часы, компьютер. Именно из-за наличия такой системы корпорация владеет огромным количеством информации о своих пользователях и в дальнейшем использует ее для получения прибыли. И подобных примеров на сегодняшний день можно найти целое множество.
Краткий обзор инструментов big data
Учитывая огромные объемы информации, которые необходимо хранить обрабатывать в процессе работы, следует заметить, что подобные манипуляции не могут выполняться на простых жестких дисках. А программное обеспечение, которое структурирует и анализирует накапливаемые данные — это отдельная интеллектуальная собственность и в каждом отдельном случае является авторской разработкой. При этом можно отметить наиболее популярные на сегодняшний день инструменты, на основе которых создаются такие решения:
‒ Hadoop & MapReduce;
‒ NoSQL базы данных;
‒ Инструменты класса Data Discovery.
Анализу особенностей и отличий перечисленных инструментов, а также обзору решений, которые могут предлагаться на основе данных инструментариев может быть посвящена отдельная статья. Но, в качестве примера, хотелось бы привести модель, которая, пожалуй, является на сегодняшний день одним из лидеров на рынке — это Oracle Big Data Appliance X5–2. Ориентировочная стоимость такой системы в максимальной комплектации может достигать 30 миллионов рублей за 1 стойку. Конечно, речь идет о промышленных системах премиум класса. Тем не менее, приведенный пример позволяет оценить порядок расходов, которые потребуются на реализацию подобных решений в компании. И это еще без учета узкоспециализированных специалистов и дополнительной ИТ инфраструктуры. Поэтому говорить о применении больших данных, например, в малом бизнесе не приходится.
Заключение
В современном бизнесе, практически не зависимо от специфики и индустрии, все более явно прослеживается ценность и высокая роль информации о потенциальных и текущих клиентах компании, о ее конкурентах и грядущих тенденциях на рынке. Все более это становится необходимыми условиями для того, чтобы сохранить конкуренцию в современном мире. В связи с этим и уже существующими примерами успеха внедрения big data крупными компаниями, которыми наполнен Интернет, можно предположить, что роль больших данных со временем будет только расти. Благодаря этому компании будут е лучше знать и понимать потребности своих клиентов и предлагать им наиболее релевантные и подходящие решения, а потребители смогут наслаждаться продуктами и услугами, которые наилучшим образом подходят именно им.
Литература:
- Виктор Майер-Шенбергер, Кеннет Кукьер. Большие данные. Революция, которая изменит то, как мы живём, работаем и мыслим = Big Data. A Revolution That Will Transform How We Live, Work, and Think / пер. с англ. Инны Гайдюк. — М.: Манн, Иванов, Фербер, 2014.
- Академия BIG DATA: Введение в аналитику больших массивов данных: Информация // Национальный Открытый Университет «ИНТУИТ». URL: https://www.intuit.ru/studies/courses/12385/1181/info (дата обращения: 30.06.2018).
- Аналитический обзор рынка Big Data // Хабр. URL: https://habr.com/company/moex/blog/256747/ (Дата обращения: 30.06.2018).
- Streamline Your Big Data Platform // ORACLE. URL: https://www.oracle.com/big-data/index.html (Дата обращения: 30.06.2018)
- MapReduce and Teradata Aster SQL-MapReduce // Teradata. URL: https://www.teradata.com/products-and-services/Teradata-Aster/teradata-aster-sql-mapreduce (Дата обращения: 30.06.2018)
Основные термины (генерируются автоматически): данные, информация, компания, объем данных, принцип работы, быстрая обработка, обработка данных, программное обеспечение, современный бизнес, транзакционная система.
Big Data — это разнообразные данные больших объемов, которые хранятся на цифровых носителях. В их число входит общая статистика рынков и личные данные пользователей: информация о транзакциях и платежах, покупках, перемещениях и предпочтениях аудитории.
Объем больших данных исчисляется терабайтами. Это и тексты, и фотографии, и машинный код. Такой массив информации просто невозможно проанализировать силами человека или с помощью обычного компьютера, для этого нужны специальные инструменты.
Технологии, связанные с хранением и обработкой больших данных, также называют Big Data.
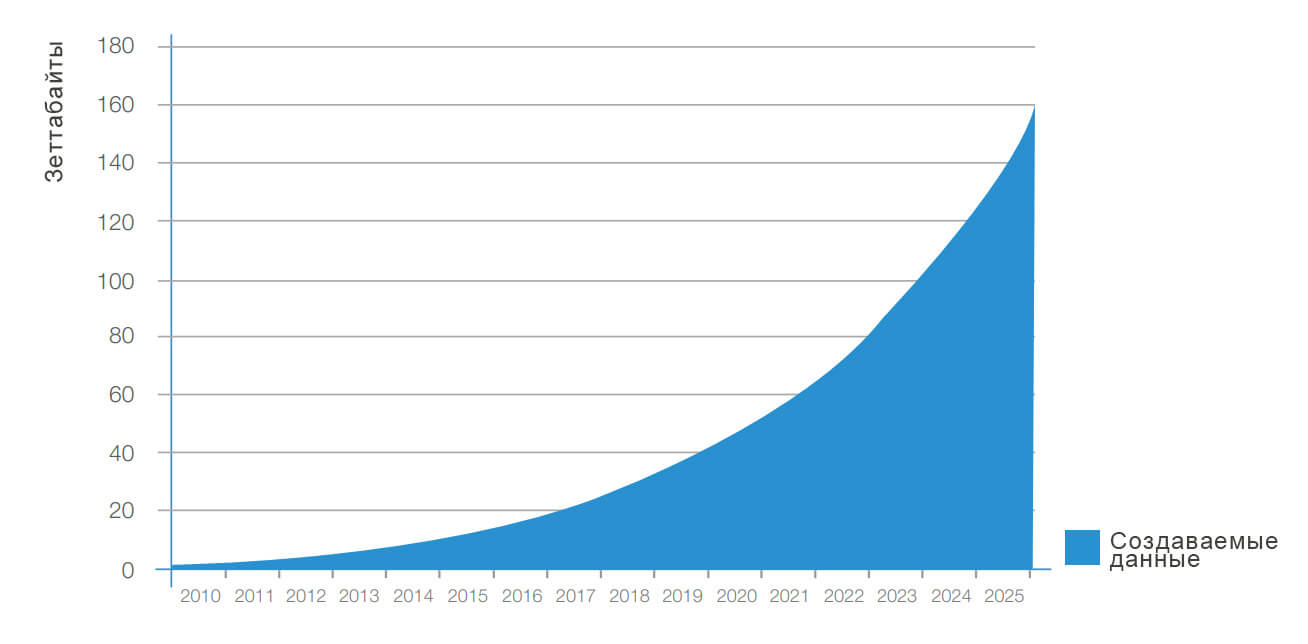
Прогноз роста больших данных в мире. Источник
Характеристики Big Data
Большие данные отличают от обычных наличие признаков «VVV».
Volume (объем) — физический размер данных, их вес и количество места, которое они занимают. Поток таких данных может составлять от 100 Гб в сутки.
Velocity (скорость) — объем информации увеличивается с большой скоростью, в геометрической прогрессии, и требует быстрой обработки и анализа.
Variety (разнообразие) — данные неоднородны и поступают в разных форматах: текст, картинки, голосовые сообщения, транзакции. Они могут быть неупорядоченными, структурированными полностью или частично.
Отдельные IT-компании выделяют дополнительные аспекты работы с большими данными.
Variability (изменчивость) — поток информации неоднороден, случаются всплески или спады. Это осложняет её обработку и анализ.
Value (ценность) — описывает как сложность информации для обработки, так и её степень важности. Для бизнеса особо актуален вопрос целесообразности затрат на обработку данных.
Visualization (визуализация) — возможность наглядно представить результаты анализа, чтобы упростить их восприятие человеком.
Veracity (достоверность) — точность и достоверность самих данных, а также корректность способа, которым получены. Неточности ведут к ошибкам в анализе.
Зачем нужны большие данные
Большие данные применяются во многих отраслях: банки, страхование, ритейл, здравоохранение, логистика, наука, маркетинг. Везде, где можно собрать большой объем информации и проанализировать его.
Отрасли, которые используют BigData. Источник
Перед BigData стоит три глобальных задачи:
Строить модели. Систематизировать данные, находить причинно-следственные связи. Это помогает понять, как работают сложные системы, делает их прозрачными.
Производители автомобилей Toyota изучили поведение водителей в момент аварии и разработали систему безопасности. Она анализирует манеру вождения и срабатывает, если человек за рулем перепутал педали.
Поисковый отряд «Лиза Алерт» совместно с «Билайн.Поиск» запустили нейросеть, чтобы обрабатывать фотографии со спутников. А еще они используют алгоритм, который вычисляет потенциальных свидетелей и высылает им информацию о пропавшем человеке.

Оптимизировать процессы. Автоматизировать рутинные или трудозатратные этапы, повысить точность расчетов и экономить ресурсы. Например, сервисы такси автоматически рассчитывают стоимость поездки с учетом спроса, пробок и погоды.
«Магнитогорский металлургический комбинат» внедрил систему, которая в режиме реального времени анализирует параметры плав и выдает рекомендации оператору цеха, что позволяет минимизировать издержки.
Amazon оптимизирует продажи и обновляет цены на сайте примерно каждый 10 минут. Также предлагает дополнительные скидки, после добавления товара в корзину, чтобы уменьшить число брошенных товаров.
Розничная сеть Target показывает разную стоимость товаров для жителей престижных и обычных районов, чтобы максимизировать выручку.
Делать прогнозы. Бизнес с помощью аналитики предсказывает поведение покупателей и спрос, планирует продажи и денежные потоки. Искусственный интеллект эффективнее врачей может выявлять болезни на ранней стадии.
Магазины предлагают персональные рекомендации и скидки для покупателей, которые с большей вероятностью им понравятся.
Застройщики с помощью систем динамического ценообразования определяют максимально выгодную стоимость объектов недвижимости на данный момент, прогнозируют прибыль и выполнение плана продаж.
Как работает технология больших данных
Работа с большими данными происходит в несколько этапов:
- сбор информации из разных источников;
- размещение данных в хранилище;
- обработка и анализ.
Сбор информации
Информация окружает нас повсюду. Социальные сети, поисковые системы, гаджеты, карты лояльности, данные GPS-трекеров, онлайн-кассы генерируют большие потоки данных каждую минуту. Источники Big Data можно разделить на три типа: социальные, машинные и транзакционные.
Социальные — создаются людьми. Информация, которую загружают или создают пользователи интернета: фотографии, электронные письма, сообщения, статьи, записи в блогах. Сюда же относят социально-демографическую статистику стран и компаний.
Транзакционные — возникают при совершении различных операций. Это покупки, переводы денег, поставки товаров, операции с банкоматами, переходы по ссылкам, поисковые запросы.
Машинные — информация с датчиков и устройств. В том числе интернет вещей — данные, которыми устройства обмениваются между собой. Например, датчики внутри автомобилей, метеорологические приборы, смартфоны, умные колонки и т.д.
Хранение
Большие объемы информации требуют больших мощностей для размещения. У компании, которая собирает Big Data, есть три варианта, где хранить данные:
- На собственных серверах. Предприятие самостоятельно закупает, настраивает и обслуживает оборудование.
- Облачное хранение. Фирма арендует место у сторонней компании за плату. Такую услугу предоставляют Amazon, Microsoft или Google. Ряд платформ, помимо хранения, предлагают готовые решения для обработки данных, например Oracle Exadata.
- Публичные большие данные. Хранятся облачно либо на частных серверах, доступ к базе предоставляется бесплатно.
У различных видов хранения есть свои плюсы и минусы:
1. На своём сервере. Это может быть дешевле, но вопросы безотказности, безопасности и поддержки вы должны будете решать сами.
2. В облаке. Это может быть дороже, но вопросы безотказности, безопасности и поддержки будут решаться на стороне облака.
Анализ
Существует 4 вида аналитики, которые отличаются по задачам, уровню сложности и участию людей.
Описательная — самая простая форма аналитики, которая описывает текущую ситуацию с помощью простых арифметических операций. Используется в счетчиках событий (лайков, репостов), веб-аналитике, социологических опросах, анализе продаж. Результаты описательной аналитики понятны широкому кругу лиц.
Диагностическая — выявляет закономерности и отклонения от нормы, ищет причины событий. Использует статистические методы. Помогает понять, что привело к поломке автомобиля или падению продаж.
Предиктивная — исследует тенденции и закономерности, чтобы прогнозировать события в будущем. Использует алгоритмы, основанные на вероятностях, и машинное обучение. Помогает предсказывать поведение покупателей, объем выручки, определять кредитный рейтинг заемщика.
Предписательная — анализирует разные сценарии развития событий, предлагает наиболее эффективные действия в текущей ситуации. Использует более сложные математические алгоритмы, машинное обучение и Data Maning. Помогает оптимизировать производство и бизнес-процессы, предотвратить аварии или убытки.
Методы и техники анализа и обработки
Рассмотрим основные методы и техники работы с большими данными.
Краудсорсинг — ручной анализ, к которому привлекают большое количество интернет-пользователей. Например, фильтрация цен или поиск контента с определенными параметрами.
Визуализация — построение графиков и визуальных моделей. Они упрощают понимание результатов анализа.
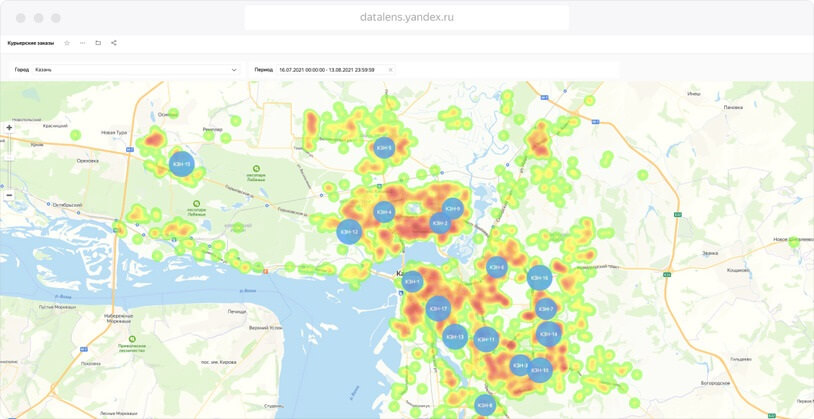
Компания Kazan Express использовала визуализацию геоданных для открытия новых пунктов выдачи. Источник
Машинное обучение — искусственный интеллект ищет закономерности и делает прогнозы с помощью математических методов, в том числе распознает образы. Прогнозирование помогает предсказывать поведение людей и принимать эффективные решения.
Имитационное моделирование — на основании данных строится модель системы, которая существует в реальности. Над ней проводят эксперименты, чтобы имитировать события и понимать, как они влияют на систему.
Смешение и интеграция данных — способ объединить данные из разных источников, чтобы дополнять и увеличивать общую базу.
Data Mining — глубинный анализ, структурирует и выявляет закономерности. Использует математические алгоритмы и статистические методы, например дерево принятия решений или нейронные сети. Data Mining — это совокупность различных методов.
Big Data в маркетинге
Для маркетологов наибольшее значение имеют четыре типа данных:
- о клиентах — социально-демографические, поведенческие, предпочтения, интересы;
- о конкурентах — цены, клиенты, реклама, продажи;
- об операциях — метрики маркетинговых кампаний;
- о финансах — продажи, прибыль, издержки.
Практические задачи бизнеса и маркетинга, которые помогают решать большие данные:
Сегментировать рынок. Точнее разбить потребителей на группы по интересам, предпочтениям, способам покупки.
Создать портрет целевой аудитории. Собрать и систематизировать подробные данные о текущих клиентах.
Персонализировать рекламу. Интернет-маркетинг использует большие данные, чтобы оптимизировать таргетированную и контекстную рекламу. Повысить кликабельность, снизить цену за клик, настроить ремаркетинг.
Прогнозировать поведение потребителей. Предсказывать реакции на рекламную кампанию, спрос и модели потребления.
Создавать и совершенствовать продукты. Анализировать причины популярности востребованных товаров, выявлять недостатки продукта и потребности клиентов.
Оптимизировать издержки. Снижать расходы на рекламу и продвижение, на логистику, управлять товарными запасами и трудовыми ресурсами.
Персонализировать предложения. Увеличить количество повторных и кросс-продаж. Рекомендовать пользователю актуальные и интересные продукты, предоставлять акции и скидки индивидуально.
Подобный блок есть в каждом маркетплейсе. Алгоритмы предлагают пользователю продукты на основе его предпочтений и ранее просмотренных товаров
Big Data и персональные данные
Значительную часть Big Data составляют персональные данные. Это информация, которую прямо или косвенно можно отнести к конкретному пользователю. Для сбора и обработки персональных данных компания должна получить согласие пользователя. Например, попросить поставить галочку в соответствующем поле при подписке или разместить предупреждение на сайте.

Форма на сайте Elizavecca
Для аналитики большие данные шифруют и обезличивают, но этого недостаточно для обеспечения безопасности. В российском секторе интернета происходит от 10 случаев кражи баз в год. При этом большая часть происходит по вине сотрудников компании.
Пользователи не могут контролировать утечку и зачастую в полной мере не представляют объем и разновидность данных, которые они передают компаниям.
Главные мысли
