По мере того, как вы продвигаетесь по карьерной лестнице в качестве разработчика, вам нужно будет все больше и больше думать об архитектуре программного обеспечения и проектировании систем. Важно уметь разрабатывать эффективные системы и идти на компромисс в масштабах. Системное проектирование — это обширная область, которая включает в себя множество важных концепций. Фундаментальной концепцией системного проектирования является теорема CAP. Понимание теоремы CAP является ключом к пониманию того, как проектировать сильные распределенные системы. Сегодня мы углубимся в теорему CAP, объясняя ее значение, ее компоненты и многое другое.
Содержание
- Что такое теорема CAP?
- Доказательство теоремы CAP
- Объяснение согласованности, доступности и допустимости разделов
- Последовательность
- Доступность
- Допуск на разделение
- CAP-теорема NoSQL базы данных
- Базы данных CA
- Базы данных CP
- Базы данных AP
- Теорема CAP и микросервисы
- Подведение итогов и следующие шаги
Что такое теорема CAP?
Теорема CAP, или теорема Брюера, является фундаментальной теоремой в области проектирования систем. Впервые он был представлен в 2000 году Эриком Брюером, профессором информатики в Калифорнийском университете в Беркли, во время выступления о принципах распределенных вычислений. В 2002 году профессора Массачусетского технологического института Нэнси Линч и Сет Гилберт опубликовали доказательство гипотезы Брюера. Теорема CAP утверждает, что распределенная система может одновременно обеспечивать только два из трех свойств: согласованность, доступность и устойчивость к разделению. Теорема формализует компромисс между согласованностью и доступностью при наличии раздела.
Распределенная система — это совокупность компьютеров, которые работают вместе, образуя единый компьютер для конечных пользователей. Все распределенные машины имеют одно общее состояние и работают одновременно. В распределенных системах пользователи должны иметь возможность связываться с любой из распределенных машин, не зная, что это только одна машина. Сеть распределенной системы хранит свои данные не только на одном узле, но и на нескольких физических или виртуальных машинах одновременно.
Доказательство теоремы CAP
Давайте посмотрим на простое доказательство теоремы CAP. Представьте себе распределенную систему, состоящую из двух узлов:
Распределенная система действует как обычный регистр со значением переменной X. Произошел сетевой сбой, который приводит к разделению сети между двумя узлами в системе. Конечный пользователь выполняет запрос записи, а затем запрос чтения. Давайте рассмотрим случай, когда каждый запрос обрабатывает другой узел системы. В этом случае у нашей системы есть два варианта:
- Может выйти из строя по одному из запросов, нарушив доступность системы
- Он может выполнять оба запроса, возвращая устаревшее значение из запроса на чтение и нарушая согласованность системы.
Система не может успешно обработать оба запроса, одновременно гарантируя, что чтение возвращает последнее значение, записанное при записи. Это связано с тем, что результаты операции записи не могут быть переданы с узла A на узел B из-за сетевого раздела.
Объяснение согласованности, доступности и допустимости разделов
Теперь, когда у нас есть базовое понимание теоремы CAP, давайте разберемся с аббревиатурой и обсудим значения согласованности, доступности и допустимости разделов.
Последовательность
В согласованной системе все узлы одновременно видят одни и те же данные. Если мы выполняем операцию чтения в согласованной системе, она должна возвращать значение самой последней операции записи. При чтении все узлы должны возвращать одни и те же данные. Все пользователи видят одни и те же данные одновременно, независимо от узла, к которому они подключены. Когда данные записываются на один узел, они затем реплицируются на другие узлы в системе.
Доступность
Когда доступность присутствует в распределенной системе, это означает, что система остается работоспособной все время. На каждый запрос будет получен ответ независимо от индивидуального состояния узлов. Это означает, что система будет работать, даже если несколько узлов не работают. В отличие от согласованной системы, нет гарантии, что ответ будет самой последней операцией записи.
Допуск на разделение
Когда распределенная система встречает раздел, это означает разрыв связи между узлами. Если система терпима к разделам, система не откажет, независимо от того, отбрасываются ли сообщения или задерживаются между узлами внутри системы. Чтобы иметь допуск к разделению, система должна реплицировать записи по комбинациям узлов и сетей.
CAP-теорема NoSQL базы данных
Базы данных NoSQL отлично подходят для распределенных сетей. Они позволяют горизонтальное масштабирование и могут быстро масштабироваться на нескольких узлах. Решая, какую базу данных NoSQL использовать, важно помнить о теореме CAP. NoSQL базы данных можно классифицировать на основе двух поддерживаемых ими функций CAP:
Базы данных CA
Базы данных CA обеспечивают согласованность и доступность на всех узлах. К сожалению, базы данных CA не могут обеспечить отказоустойчивость. В любой распределенной системе разделы неизбежны, а это означает, что этот тип базы данных не очень практичный выбор. При этом вы все равно можете найти базу данных CA, если она вам нужна. Некоторые реляционные базы данных, такие как PostgreSQL, обеспечивают согласованность и доступность. Вы можете развернуть их на узлах с помощью репликации.
Базы данных CP
Базы данных CP обеспечивают согласованность и устойчивость к разделам, но не доступность. Когда происходит разделение, система должна отключить несогласованные узлы, пока раздел не будет исправлен. MongoDB — это пример базы данных CP. Это система управления базами данных (СУБД) NoSQL, которая использует документы для хранения данных. Считается, что он не имеет схемы, что означает, что для него не требуется определенная схема базы данных. Он обычно используется в больших данных и приложениях, работающих в разных местах. Система CP структурирована так, что есть только один первичный узел, который получает все запросы на запись в данном наборе реплик. Вторичные узлы реплицируют данные в первичных узлах, поэтому в случае отказа первичного узла вторичный узел может заменить.
Базы данных AP
Базы данных AP обеспечивают доступность и устойчивость к разделам, но не согласованность. В случае раздела доступны все узлы, но не все они обновлены. Например, если пользователь пытается получить доступ к данным с неисправного узла, он не получит самую последнюю версию данных. Когда раздел в конечном итоге будет разрешен, большинство баз данных AP синхронизируют узлы для обеспечения согласованности между ними. Apache Cassandra — это пример базы данных AP. Это база данных NoSQL без первичного узла, что означает, что все узлы остаются доступными. Cassandra обеспечивает возможную согласованность, потому что пользователи могут повторно синхронизировать свои данные сразу после разрешения раздела.
Теорема CAP и микросервисы
Микросервисы определяются как слабо связанные сервисы, которые можно независимо разрабатывать, развертывать и поддерживать. Они включают свой собственный стек, базу данных и модель базы данных и обмениваются данными друг с другом через сеть. Микросервисы стали особенно популярными в гибридных облачных и мультиоблачных средах. А также широко используются в локальных центрах обработки данных. Если вы хотите создать приложение для микросервисов, вы можете использовать теорему CAP, чтобы помочь вам определить базу данных, которая наилучшим образом соответствует вашим потребностям.
Подведение итогов и следующие шаги
Поздравляем с тем, что вы сделали первый шаг в изучении теоремы CAP и распределенных систем! Распределенные системы обеспечивают меньшую задержку, масштабируемость, повышенную взаимосвязь и многое другое. Теорема CAP очень важна для распределенных систем и системного проектирования в целом. Сегодня мы многое рассмотрели, но еще многое предстоит узнать о распределенных системах. Вот некоторые рекомендуемые темы для дальнейшего изучения:
- Распределенные хранилища данных
- Алгоритмы распределенной системы
- Атомарность
Во время моего первого опыта работы с распределенными системами я постоянно сталкивался с некой CAP-теоремой, пришлось изрядно покопать, чтобы изучить и осознать её со всех сторон. Я не являюсь мастером баз данных, но надеюсь, что мое маленькое исследование мира распределённых систем будет полезно для обычных разработчиков. В статье я расскажу о том, что такое CAP, его проблемы и альтернативы, а также рассмотрим некоторые популярные системы баз данных через CAP призму.
CAP теорема
Эта теорема была представлена на симпозиуме по принципам распределенных вычислений в 2000 году Эриком Брюером. В 2002 году Сет Гилберт и Нэнси Линч из MIT опубликовали формальное доказательство гипотезы Брюера, сделав ее теоремой.
По словам Брюера, он хотел, чтобы сообщество начало дискуссию о компромиссах в распределённых системах и уже спустя некоторое количество лет начал вносить в неё поправки и оговорки.
Что стоит за CAP
В CAP говорится, что в распределенной системе возможно выбрать только 2 из 3-х свойств:
- C (consistency) — согласованность. Каждое чтение даст вам самую последнюю запись.
- A (availability) — доступность. Каждый узел (не упавший) всегда успешно выполняет запросы (на чтение и запись).
- P (partition tolerance) — устойчивость к распределению. Даже если между узлами нет связи, они продолжают работать независимо друг от друга.
Уже есть достаточно наглядных доказательств этой теоремы, поэтому дам ссылки на университет Баумана и доказательство в виде сервиса «Позвони, напомню!».
В основном это всё треугольник
Многие статьи сводятся к вот такому вот простому треугольнику.

Применяем на практике
Для применения CAP теоремы на практике, я выбрал 3 наиболее, на мой взгляд, подходящие и достаточно популярные системы баз данных: Postgresql, MongoDB, Cassandra.
Посмотрим на Postgresql
Следующие пункты относятся к абстрактной распределенной БД Postgresql.
- Репликация Master-Slave — одно из распространенных решений
- Синхронизация с Master в асинхронном / синхронном режиме
- Система транзакций использует двухфазный коммит для обеспечения consistency
- Если возникает partition, вы не можете взаимодейстовать с системой (в основном случае)
Таким образом, система не может продолжать работу в случае partition, но обеспечивает strong consistency и availability. Это система CA!
Посмотрим на MongoDB
Следующие пункты относятся к абстрактной распределенной БД MongoDB.
- MongoDB обеспечивает strong consistency, потому что это система с одним Master узлом, и все записи идут по умолчанию в него.
- Автоматическая смена мастера, в случае отделения его от остальных узлов.
- В случае разделения сети, система прекратит принимать записи до тех пор, пока не убедится, что может безопасно завершить их.
Таким образом, система может продолжать работу в случае разделения сети, но теряется CAP-availability всех узлов. Это CP система!
Посмотрим на Cassandra
Cassandra использует схему репликации master-master, что фактически означает AP систему, в которой разделение сети приводит к самодостаточному функционированию всех узлов.
Казалось бы всё просто… Но это не так.
Проблемы CAP
На тему проблем в CAP теореме написано множество подробных и интересных статей, здесь, на Хабре, поэтому я оставлю ссылку на CAP больше не актуален и мифы о CAP теореме. Обязательно почитайте их, но относитесь к каждой статье, как к своего рода новому взгляду и не принимайте слишком близко к сердцу, потому что одни ругают, другие хвалят. Сам же я не буду слишком углублятся, а постараюсь выдать некоторую необходимую компиляцию.
Итак, проблемы CAP теоремы:
- Далёкие от реального мира определения
- В рамках разработки, выбор в основном лежит между CP и AP
- Множество систем — просто P
- Чистые AP и CP системы могут быть не тем, что ожидаешь
Что не так с определениями?
Consistency в CAP фактически означает линеаризуемость (и ее действительно трудно достичь). Чтобы объяснить, что такое линеаризуемость, давайте посмотрим на следующую картинку:

В описанном случае рефери закончил игру, но не каждый клиент получает один и тот же результат. Чтобы сделать его систему линеаризованной, нам нужно мгновенно синхронизировать данные между рефери и другими источниками данных, чтобы, когда рефери закончит игру, каждый клиент получил правильную информацию.
Availability в CAP, исходя из определения имеет две серьёзные проблемы. Первая — нет понятия частичной доступности, или какой-то её степени (проценты например), а есть только полная доступность. Вторая проблема — неограниченное время ответа на запросы, т.е. даже если система отвечает час, она всё ещё доступна.
Устойчивость к распределению не включает в себя упавшие узлы, и вот почему:
- По определению. В availability так и прописано «…every node (if not failed) always…»
- Исходя из доказательства. Доказательства CAP теоремы гласят что на узлах должен исполняться некоторый код.
- Ну и немного моих (и не только) домыслов. В случае падения узла, система может восстановиться, пообщаться с другими узлами и продолжить работу как ни в чем ни бывало. В случае разделения сети — придётся ждать восстановления соединения.
Поэтому, нужно помнить про способность системы восстанавливаться, но за рамками CAP теоремы.
AP / CP выбор
Коммуникация узлов между собой обычно происходит через асинхронную сеть, которая может задерживать или удалять сообщения. Интернет и все наши центры обработки данных обладают этим свойством, и это не маловероятные инциденты, поэтому CA системы в рамках разработки рассматриваются крайне редко.
Многие системы — просто P
Представьте систему, в которой два узла (Master, Slave) и клиент. Если вдруг вы потеряли связь с Master, клиент может читать из Slave, но не может писать — нет CAP-availability.
Ок, вроде CP система, но если Master и Slave синхронизируются асинхронно, то клиент, может запросить данные от Slave раньше успешной синхронизации — теряем CAP-consistency.

Чистые AP и CP системы
Чистые AP системы, могут включать в себя просто 2 генератора чисел. Чистые CP системы, могут вообще не быть доступны, т.к. буду пытаться придти к согласованному состоянию и не будут нам отвечать. Идём дальше, CP системы дают нам не ожидаемый нами strong consistency, а eventual consistency. О нём поговорим чуть позже.
Как с этим жить
В конце концов, это всего лишь попытка классифицировать что-то абстрактное, поэтому вам не нужно изобретать велосипед. Я рекомендую использовать следующий подход при попытке работать с распределенными БД:
- Помните об определениях CAP и об их ограничениях.
- Используйте теорему PACELC вместо CAP, она позволяет взглянуть на систему ещё с одного ракурса.
- Помните про принципы ACID / BASE и насколько они применимы к вашей системе.
- Любые телодвижения следует делать, учитывая проект, над которым вы работаете.
PACELC
Теорема PACELC была впервые описана и формализована Даниелом Дж. Абади из Йельского университета в 2012 году. Поскольку теорема PACELC основана на CAP, она также использует его определения.
Вся теорема сводится к IF P -> (C or A), ELSE (C or L).
Latency — это время, за которое клиент получит ответ и которое регулируется каким-либо уровнем consistency. Latency (задержка), в некотором смысле представляет собой степень доступности.

Немного о BASE
BASE — это своеобразный контраст ACID, который говорит нам, что истинная согласованность не может быть достигнута в реальном мире и не может быть смоделирована в высокомасштабируемых системах.
Что стоит за BASE:
- Basic Availability. Система отвечает на любой запрос, но этот ответ может быть содержать ошибку или несогласованные данные.
- Soft-state. Состояние системы может меняться со временем из-за изменений конечной согласованности.
- Eventual consistency (конечная согласованность). Система, в конечном итоге, станет согласованной. Она будет продолжать принимать данные и не будет проверять каждую транзакцию на согласованность.
Меня несколько раз спрашивали о том, что лучше ACID или BASE — это зависит от вашего проекта. Например, если ваши данные не критичны, и пользователь действительно заботится о скорости взаимодействия, BASE будет лучшим вариантом. Если всё наоборот — ACID поможет вам сделать систему максимально надежной с точки зрения данных.
Свежий взгляд
Теперь, когда мы знаем о большинстве подводных камней, давайте попробуем рассмотреть те же самые популярные системы баз данных через призму полученных знаний.
Postgresql
Postgresql действительно допускает множество различных конфигураций системы, поэтому их очень сложно описать. Давайте просто возьмем классическую Master-Slave репликацию с реализацией через Slony.
- Система работает в соответствии с ACID (существует пара проблем с двухфазным коммитом, но это вне рамок статьи).
- В случае разрыва связи, Slony попытается переключиться на новый Master, и у нас есть новый мастер с его согласованностью.
- Когда система функционирует в нормальном режиме, Slony делает все, чтобы достичь strong consistency. На самом деле, ACID — причина большой задержки в этой системе.
- Классификация системы — PC / EC (A).
MongoDB
Давайте узнаем что-то новое о MongoDB:
- Это ACID в ограниченном смысле на уровне документа.
- В случае распределенной системы — it’s all about that BASE.
- В случае отсутствия разделений сети, система гарантирует, что чтение и запись будут согласованными.
- Если Master узел упадёт или потеряет связь с остальной системой, некоторые данные не будут реплицированы. Система выберет нового мастера, чтобы оставаться доступной для чтения и записи. (Новый мастер и старый мастер несогласованы).
- Система рассматривается как PA / EC (A), так как большинство узлов остаются CAP-available в случае разрыва. Помните, что в CAP MongoDB обычно рассматривается как CP. Создателль PACELC, Даниэль Дж. Абади, говорит, что существует гораздо больше проблем с согласованностью, чем с доступностью, поэтому PA.
Cassandra
- Предназначена для «скоростного» взаимодействия (low-latency interactions).
- ACID на уровне записи.
- В случае распределенной системы — it’s all about that BASE.
- Если возникает разрыв связи, остальные узлы продолжают функционировать.
- В случае нормального функционирования — система использует уровни согласованности для уменьшения задержки.
- Система рассматривается как PA / EL (A).
Выводы
- Компромиссы распределённых систем — это то, с чего стоит начинать процесс проектирования.
- Достаточно трудно классифицировать абстрактную систему, гораздо лучше сначала сформировать требования исходя из технического задания, а уже затем правильно сконфигурировать нужную систему баз данных.
- Не перетруждайтесь, мы ведь просто любопытные разработчики, если в чем-то есть сомнения — обратитесь к эксперту.
Спасибо за внимание!
Автор: svinopapka
Источник
Краткое введение в тему.
https://gbcdn.mrgcdn.ru/uploads/post/676/og_cover_image/b8801415ef8996f3e4f5b448255abf4e

Это тоже база данных, но ручная
Здравствуйте!
Поговорим об базах данных. Сегодня транзакции, ACID и CAP-теорема — теория, которая важна для следующих статей.
Транзакции
Транзакция — это набор действий с данными, объединенный в логическую единицу. Она либо выполняется целиком, либо нет. Классический пример с операцией перевода денег со счета на счет:
Начать транзакцию
прочесть баланс на счету номер 5
уменьшить баланс на 10 денежных единиц
сохранить новый баланс счёта номер 5
прочесть баланс на счету номер 7
увеличить баланс на 10 денежных единиц
сохранить новый баланс счёта номер 7
Окончить транзакциюЕсли эти операции выполнять вне транзакции, то ошибка в любой из них оставит оба счета в несогласованном состоянии: например, выйдет так, что деньги снимутся с одного счета, а на другой не придут. С транзакцией таких проблем нет — при ошибке откатятся все операции и для пользователя ничего не изменится.
Все звучит просто, когда с базой данных работает один пользователь: он выполняет транзакции одна за другой и не имеет никаких проблем с тем, что одна транзакция помешает другой. Все меняется, когда пользователей становится много.
Вот что может случиться при параллельном выполнении неизолированных транзакций.
Потерянное обновление
Когда две транзакции записывают разные значения в одну и ту же ячейку, одно из изменений теряется.
Грязное чтение
Когда читаются данные, которые в этот момент изменяются транзакцией, а потом транзакция откатывается и данные исчезают.
Неповторяющееся чтение
Когда несколько раз читаются данные, которые в этот момент изменяются транзакцией — каждый раз данные могут отказаться другими.
Фантомное чтение
Одна транзакция в ходе своего выполнения несколько раз выбирает множество строк по одним и тем же критериям. Другая транзакция в интервалах между этими выборками добавляет или удаляет строки или изменяет столбцы некоторых строк, используемых в критериях выборки первой транзакции, и успешно заканчивается. В результате получится, что одни и те же выборки в первой транзакции дают разные множества строк.
Изоляция транзакций
Чтобы параллельные транзакции могли выполняться, не мешая друг другу, придумали концепцию изоляции транзакций. Всего есть четыре уровня изоляции, но некоторые базы данных вводят свои уровни.
Чтение неподтверждённых данных (read uncommitted)
Самый низкий уровень изоляции. Можно свободно читать незафиксированные изменения других транзакций, но запись идет строго последовательно. Таким образом, исключается только проблема потерянных обновлений: гарантируется, что в итоге в ячейку запишут нужное значение все транзакции по очереди.
Обычно для этого используют блокировку на запись ячеек, предназначенных для изменения в рамках текущей транзакции. На чтение блокировки не ставятся.
Чтение подтверждённых данных (read committed)
Можно свободно читать все изменения своей транзакции и зафиксированные изменения чужих транзакций. Исключаются потерянные обновления и грязное чтение, остаются проблемы неповторяемых чтений и фантомов.
Повторяемое чтение (repeatable read)
Можно читать все изменения только своей транзации. Данные, измененные другими транзакциями, недоступны. Остается только проблема фантомных чтений.
Сериализуемый (serializable)
Транзакции полностью изолируются друг от друга, каждая выполняется так, как будто параллельных транзакций не существует.
ACID
Это набор из четырех требований к транзакционной системе, обеспечивающих максимально надежную и предсказуемую работу. Не все базы данных полностью реализуют ACID.
Атомарность (atomicity)
Атомарность гарантирует, что каждая транзакция будет выполнена полностью или не будет выполнена совсем. Не допускаются промежуточные состояния.
Согласованность (consistency)
Согласованность — это требование, подразумевающее, что в результате работы транзакции данные будут допустимыми. Это вопрос не технологии, а бизнес-логики: например, если количество денег на счете не может быть отрицательным, логика транзакции должна проверять, не выйдет ли в результате отрицательных значений.
Изолированность (isolation)
Гарантия того, что параллельные транзакции не будут оказывать влияния на результат других транзакций. Мы разобрались с изоляцией выше.
Долговечность (durability)
Изменения, получившиеся в результате транзакции, должны оставаться сохраненными вне зависимости от каких-либо сбоев. Иначе говоря, если пользователь получил сигнал о завершении транзакции, он может быть уверен, что данные сохранены.
CAP-теорема

Она гласит, что в распределенной системе можно обеспечить только два свойства из трех: согласованность, доступность и устойчивость к разделению. Помогает понимать, как конкретная распределенная система будет работать и чего от нее ожидать.
Согласованность данных (consistency)
Когда во всех узлах в каждый момент времени данные согласованы друг с другом, то есть не противоречат друг другу. Если в одном из узлов в ячейке базы данных есть данные, такие же данные есть на всех остальных узлах.
Доступность (availability)
Когда любой запрос может быть обработан системой, вне зависимости от ее состояния.
Устойчивость к разделению (partition tolerance)
Когда расщепление системы на несколько изолированных секций не приводит к некорректному отклику от каждой из секций: отвалилась сеть между двумя узлами, но каждый из них может корректно отвечать своим клиентам.
Все распределенные базы данных так или иначе в лучшем случае реализуют два свойства из трех, жертвуя оставшимся.
В следующей статье — о редких базах данных, которых вы не увидите в обычных проектах. Там нам и пригодится вся эта теория.
CAP-теорема — утверждение о том, что в распределённых системах нельзя одновременно добиться трёх свойств:
- Consistency — на всех не отказавших узлах одинаковые (с точки зрения пользователя) данные
- Availability — запросы ко всем не отказавшим узлам возвращают ответ
- Partition tolerance — даже если связь в системе стала нестабильной (вплоть до разделения системы на куски), но узлы работают, то система в целом продолжает работать
Формально мы это не формулировали и не доказывали.
Оригинальная формулировка — Brewer’s Conjecture (2000), а формализовано в работе Gilbert & Lynch (2004).
Там есть много тонкостей с тем, что такое «не отказавший узел», «одинаковые данные», «разрыв связи», «система продолжает работать», «когда система всё-таки окончательно ломается и считается недоступной» и тому подобное.
Для общей эрудиции выглядят неплохо статьи[1][2]
Классификация алгоритмов
А вот алгоритмы, которые удовлетворяют хотя бы двум свойствам, можно нарисовать на диаграмма Венна:
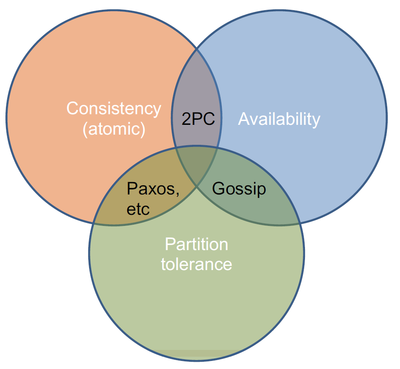
Дальше идут объяснения с лекции, они отличаются в разных источниках (например, где-то 2PC идёт вместе с Paxos в CP, а не в CA[3]), а где-то совпадают с лекцией[4], а где-то считают, что не-partition tolerance не нужно[5].
- Если мы хотим согласованность и доступность, то используем протокол двухфазного коммита: он гарантирует нам согласованное состояние глобально во всей системе и мы всегда можем обслуживать запросы (если только не упал узел с соответствующими данными). Но если потерялась связь (а узлы не упали), то какие-то запросы нельзя обработать, потому что часть данных может быть в одной половине, а часть в другой. Каждый кусок всё ещё будет работать по отдельности, но глобальные транзакции выполнять мы не сможем.
- Иногда нам не так важна согласованность и мы согласны на простую eventual consistency — это когда информация может быть доступна не сразу везде, а только через какое-то время, если система здорова. Сюда идут gossip-протоколы.
- Если мы хотим согласованность и толерантность к разделению, то надо жертвовать доступностью. Например, при помощи Paxos мы можем хранить все данные сразу на всех узлах, но тогда узлы, оказавшиеся в меньшинстве, ничего сделать не могут.