Have you ever seen an advertisement for a landscaper, house painter, or some other tradesperson that starts with the headline, “Cheap, Fast, and Good: Pick Two”?
The CAP theorem applies a similar type of logic to distributed systems—namely, that a distributed system can deliver only two of three desired characteristics: consistency, availability, and partition tolerance (the ‘C,’ ‘A’ and ‘P’ in CAP).
A distributed system is a network that stores data on more than one node (physical or virtual machines) at the same time. Because all cloud applications are distributed systems, it’s essential to understand the CAP theorem when designing a cloud app so that you can choose a data management system that delivers the characteristics your application needs most.
The CAP theorem is also called Brewer’s Theorem, because it was first advanced by Professor Eric A. Brewer during a talk he gave on distributed computing in 2000. Two years later, MIT professors Seth Gilbert and Nancy Lynch published a proof of “Brewer’s Conjecture.”
More on the ‘CAP’ in the CAP theorem
Let’s take a detailed look at the three distributed system characteristics to which the CAP theorem refers.
Consistency
Consistency means that all clients see the same data at the same time, no matter which node they connect to. For this to happen, whenever data is written to one node, it must be instantly forwarded or replicated to all the other nodes in the system before the write is deemed ‘successful.’
Availability
Availability means that any client making a request for data gets a response, even if one or more nodes are down. Another way to state this—all working nodes in the distributed system return a valid response for any request, without exception.
Partition tolerance
A partition is a communications break within a distributed system—a lost or temporarily delayed connection between two nodes. Partition tolerance means that the cluster must continue to work despite any number of communication breakdowns between nodes in the system.
CAP theorem NoSQL database types
NoSQL databases are ideal for distributed network applications. Unlike their vertically scalable SQL (relational) counterparts, NoSQL databases are horizontally scalable and distributed by design—they can rapidly scale across a growing network consisting of multiple interconnected nodes. (See «SQL vs. NoSQL Databases: What’s the Difference?» for more information.)
Today, NoSQL databases are classified based on the two CAP characteristics they support:
- CP database: A CP database delivers consistency and partition tolerance at the expense of availability. When a partition occurs between any two nodes, the system has to shut down the non-consistent node (i.e., make it unavailable) until the partition is resolved.
- AP database: An AP database delivers availability and partition tolerance at the expense of consistency. When a partition occurs, all nodes remain available but those at the wrong end of a partition might return an older version of data than others. (When the partition is resolved, the AP databases typically resync the nodes to repair all inconsistencies in the system.)
- CA database: A CA database delivers consistency and availability across all nodes. It can’t do this if there is a partition between any two nodes in the system, however, and therefore can’t deliver fault tolerance.
We listed the CA database type last for a reason—in a distributed system, partitions can’t be avoided. So, while we can discuss a CA distributed database in theory, for all practical purposes a CA distributed database can’t exist. This doesn’t mean you can’t have a CA database for your distributed application if you need one. Many relational databases, such as PostgreSQL, deliver consistency and availability and can be deployed to multiple nodes using replication.
MongoDB and the CAP theorem
MongoDB is a popular NoSQL database management system that stores data as BSON (binary JSON) documents. It’s frequently used for big data and real-time applications running at multiple different locations. Relative to the CAP theorem, MongoDB is a CP data store—it resolves network partitions by maintaining consistency, while compromising on availability.
MongoDB is a single-master system—each replica set (link resides outside ibm.com) can have only one primary node that receives all the write operations. All other nodes in the same replica set are secondary nodes that replicate the primary node’s operation log and apply it to their own data set. By default, clients also read from the primary node, but they can also specify a read preference (link resides outside ibm.com) that allows them to read from secondary nodes.
When the primary node becomes unavailable, the secondary node with the most recent operation log will be elected as the new primary node. Once all the other secondary nodes catch up with the new master, the cluster becomes available again. As clients can’t make any write requests during this interval, the data remains consistent across the entire network.
Cassandra and the CAP theorem (AP)
Apache Cassandra is an open source NoSQL database maintained by the Apache Software Foundation. It’s a wide-column database that lets you store data on a distributed network. However, unlike MongoDB, Cassandra has a masterless architecture, and as a result, it has multiple points of failure, rather than a single one.
Relative to the CAP theorem, Cassandra is an AP database—it delivers availability and partition tolerance but can’t deliver consistency all the time. Because Cassandra doesn’t have a master node, all the nodes must be available continuously. However, Cassandra provides eventual consistency by allowing clients to write to any nodes at any time and reconciling inconsistencies as quickly as possible.
As data only becomes inconsistent in the case of a network partition and inconsistencies are quickly resolved, Cassandra offers “repair” functionality to help nodes catch up with their peers. However, constant availability results in a highly performant system that might be worth the trade-off in many cases.
Microservices and the CAP theorem
Microservices are loosely coupled, independently deployable application components that incorporate their own stack—including their own database and database model—and communicate with each other over a network. As you can run microservices on both cloud servers and on-premises data centers, they have become highly popular for hybrid and multicloud applications.
Understanding the CAP theorem can help you choose the best database when designing a microservices-based application running from multiple locations. For example, if the ability to quickly iterate the data model and scale horizontally is essential to your application, but you can tolerate eventual (as opposed to strict) consistency, an AP database like Cassandra or Apache CouchDB can meet your requirements and simplify your deployment. On the other hand, if your application depends heavily on data consistency—as in an eCommerce application or a payment service—you might opt for a relational database like PostgreSQL.
Related solutions
Cloud databases on IBM Cloud
Explore the range of cloud databases offered by IBM to support a variety of use cases: from mission-critical workloads, to mobile and web apps, to analytics.
IBM Cloudant
IBM Cloudant is a scalable, distributed cloud database based on Apache CouchDB and used for web, mobile, IoT and serverless applications.
DataStax Enterprise with IBM
Get this scalable, highly available, cloud-native NoSQL database built on Apache Cassandra from IBM, your single source for purchase, deployment and support.
Resources
Take the next step
IBM Cloud database solutions offer a complete portfolio of managed services for data and analytics. Using a hybrid, open source-based approach, these solutions address the data-intensive needs of application developers, data scientists and IT architects. Hybrid databases create a distributed hybrid data cloud for increased performance, reach, uptime, mobility and cost savings.
Find your IBM Cloud database solution
По мере того, как вы продвигаетесь по карьерной лестнице в качестве разработчика, вам нужно будет все больше и больше думать об архитектуре программного обеспечения и проектировании систем. Важно уметь разрабатывать эффективные системы и идти на компромисс в масштабах. Системное проектирование — это обширная область, которая включает в себя множество важных концепций. Фундаментальной концепцией системного проектирования является теорема CAP. Понимание теоремы CAP является ключом к пониманию того, как проектировать сильные распределенные системы. Сегодня мы углубимся в теорему CAP, объясняя ее значение, ее компоненты и многое другое.
Содержание
- Что такое теорема CAP?
- Доказательство теоремы CAP
- Объяснение согласованности, доступности и допустимости разделов
- Последовательность
- Доступность
- Допуск на разделение
- CAP-теорема NoSQL базы данных
- Базы данных CA
- Базы данных CP
- Базы данных AP
- Теорема CAP и микросервисы
- Подведение итогов и следующие шаги
Что такое теорема CAP?
Теорема CAP, или теорема Брюера, является фундаментальной теоремой в области проектирования систем. Впервые он был представлен в 2000 году Эриком Брюером, профессором информатики в Калифорнийском университете в Беркли, во время выступления о принципах распределенных вычислений. В 2002 году профессора Массачусетского технологического института Нэнси Линч и Сет Гилберт опубликовали доказательство гипотезы Брюера. Теорема CAP утверждает, что распределенная система может одновременно обеспечивать только два из трех свойств: согласованность, доступность и устойчивость к разделению. Теорема формализует компромисс между согласованностью и доступностью при наличии раздела.
Распределенная система — это совокупность компьютеров, которые работают вместе, образуя единый компьютер для конечных пользователей. Все распределенные машины имеют одно общее состояние и работают одновременно. В распределенных системах пользователи должны иметь возможность связываться с любой из распределенных машин, не зная, что это только одна машина. Сеть распределенной системы хранит свои данные не только на одном узле, но и на нескольких физических или виртуальных машинах одновременно.
Доказательство теоремы CAP
Давайте посмотрим на простое доказательство теоремы CAP. Представьте себе распределенную систему, состоящую из двух узлов:
Распределенная система действует как обычный регистр со значением переменной X. Произошел сетевой сбой, который приводит к разделению сети между двумя узлами в системе. Конечный пользователь выполняет запрос записи, а затем запрос чтения. Давайте рассмотрим случай, когда каждый запрос обрабатывает другой узел системы. В этом случае у нашей системы есть два варианта:
- Может выйти из строя по одному из запросов, нарушив доступность системы
- Он может выполнять оба запроса, возвращая устаревшее значение из запроса на чтение и нарушая согласованность системы.
Система не может успешно обработать оба запроса, одновременно гарантируя, что чтение возвращает последнее значение, записанное при записи. Это связано с тем, что результаты операции записи не могут быть переданы с узла A на узел B из-за сетевого раздела.
Объяснение согласованности, доступности и допустимости разделов
Теперь, когда у нас есть базовое понимание теоремы CAP, давайте разберемся с аббревиатурой и обсудим значения согласованности, доступности и допустимости разделов.
Последовательность
В согласованной системе все узлы одновременно видят одни и те же данные. Если мы выполняем операцию чтения в согласованной системе, она должна возвращать значение самой последней операции записи. При чтении все узлы должны возвращать одни и те же данные. Все пользователи видят одни и те же данные одновременно, независимо от узла, к которому они подключены. Когда данные записываются на один узел, они затем реплицируются на другие узлы в системе.
Доступность
Когда доступность присутствует в распределенной системе, это означает, что система остается работоспособной все время. На каждый запрос будет получен ответ независимо от индивидуального состояния узлов. Это означает, что система будет работать, даже если несколько узлов не работают. В отличие от согласованной системы, нет гарантии, что ответ будет самой последней операцией записи.
Допуск на разделение
Когда распределенная система встречает раздел, это означает разрыв связи между узлами. Если система терпима к разделам, система не откажет, независимо от того, отбрасываются ли сообщения или задерживаются между узлами внутри системы. Чтобы иметь допуск к разделению, система должна реплицировать записи по комбинациям узлов и сетей.
CAP-теорема NoSQL базы данных
Базы данных NoSQL отлично подходят для распределенных сетей. Они позволяют горизонтальное масштабирование и могут быстро масштабироваться на нескольких узлах. Решая, какую базу данных NoSQL использовать, важно помнить о теореме CAP. NoSQL базы данных можно классифицировать на основе двух поддерживаемых ими функций CAP:
Базы данных CA
Базы данных CA обеспечивают согласованность и доступность на всех узлах. К сожалению, базы данных CA не могут обеспечить отказоустойчивость. В любой распределенной системе разделы неизбежны, а это означает, что этот тип базы данных не очень практичный выбор. При этом вы все равно можете найти базу данных CA, если она вам нужна. Некоторые реляционные базы данных, такие как PostgreSQL, обеспечивают согласованность и доступность. Вы можете развернуть их на узлах с помощью репликации.
Базы данных CP
Базы данных CP обеспечивают согласованность и устойчивость к разделам, но не доступность. Когда происходит разделение, система должна отключить несогласованные узлы, пока раздел не будет исправлен. MongoDB — это пример базы данных CP. Это система управления базами данных (СУБД) NoSQL, которая использует документы для хранения данных. Считается, что он не имеет схемы, что означает, что для него не требуется определенная схема базы данных. Он обычно используется в больших данных и приложениях, работающих в разных местах. Система CP структурирована так, что есть только один первичный узел, который получает все запросы на запись в данном наборе реплик. Вторичные узлы реплицируют данные в первичных узлах, поэтому в случае отказа первичного узла вторичный узел может заменить.
Базы данных AP
Базы данных AP обеспечивают доступность и устойчивость к разделам, но не согласованность. В случае раздела доступны все узлы, но не все они обновлены. Например, если пользователь пытается получить доступ к данным с неисправного узла, он не получит самую последнюю версию данных. Когда раздел в конечном итоге будет разрешен, большинство баз данных AP синхронизируют узлы для обеспечения согласованности между ними. Apache Cassandra — это пример базы данных AP. Это база данных NoSQL без первичного узла, что означает, что все узлы остаются доступными. Cassandra обеспечивает возможную согласованность, потому что пользователи могут повторно синхронизировать свои данные сразу после разрешения раздела.
Теорема CAP и микросервисы
Микросервисы определяются как слабо связанные сервисы, которые можно независимо разрабатывать, развертывать и поддерживать. Они включают свой собственный стек, базу данных и модель базы данных и обмениваются данными друг с другом через сеть. Микросервисы стали особенно популярными в гибридных облачных и мультиоблачных средах. А также широко используются в локальных центрах обработки данных. Если вы хотите создать приложение для микросервисов, вы можете использовать теорему CAP, чтобы помочь вам определить базу данных, которая наилучшим образом соответствует вашим потребностям.
Подведение итогов и следующие шаги
Поздравляем с тем, что вы сделали первый шаг в изучении теоремы CAP и распределенных систем! Распределенные системы обеспечивают меньшую задержку, масштабируемость, повышенную взаимосвязь и многое другое. Теорема CAP очень важна для распределенных систем и системного проектирования в целом. Сегодня мы многое рассмотрели, но еще многое предстоит узнать о распределенных системах. Вот некоторые рекомендуемые темы для дальнейшего изучения:
- Распределенные хранилища данных
- Алгоритмы распределенной системы
- Атомарность
NoSQL databases are great for distributed networks. They allow for horizontal scaling, and they can quickly scale across multiple nodes. When deciding which NoSQL database to use, it’s important to keep the CAP theorem in mind. NoSQL databases can be classified based on the two CAP features they support:
CA databases
CA databases enable consistency and availability across all nodes. Unfortunately, CA databases can’t deliver fault tolerance. In any distributed system, partitions are bound to happen, which means this type of database isn’t a very practical choice. That being said, you still can find a CA database if you need one. Some relational databases, such as PostgreSQL, allow for consistency and availability. You can deploy them to nodes using replication.
CP databases
CP databases enable consistency and partition tolerance, but not availability. When a partition occurs, the system has to turn off inconsistent nodes until the partition can be fixed. MongoDB is an example of a CP database. It’s a NoSQL database management system (DBMS) that uses documents for data storage. It’s considered schema-less, which means that it doesn’t require a defined database schema. It’s commonly used in big data and applications running in different locations. The CP system is structured so that there’s only one primary node that receives all of the write requests in a given replica set. Secondary nodes replicate the data in the primary nodes, so if the primary node fails, a secondary node can stand-in.
AP databases
AP databases enable availability and partition tolerance, but not consistency. In the event of a partition, all nodes are available, but they’re not all updated. For example, if a user tries to access data from a bad node, they won’t receive the most up-to-date version of the data. When the partition is eventually resolved, most AP databases will sync the nodes to ensure consistency across them. Apache Cassandra is an example of an AP database. It’s a NoSQL database with no primary node, meaning that all of the nodes remain available. Cassandra allows for eventual consistency because users can resync their data right after a partition is resolved.
Эта серия статей предназначена для стойких духом инженеров — в ней мы рассмотрим существующие NoSQL технологии, их особенности и отличия от классических реляционных SQL баз. Начнём же наш обзор.
Все современные технологии хранения данных можно разделить на следующие группы:

В этой статье мы рассмотрим общие различия между SQL и NoSQL.
Классика реляционных баз данных
Как всем нам известно, реляционная модель данных — это не что иное как набор таблиц, имеющих отношения (relations) друг с другом. Приводить полное определение в рамках этой статьи я, конечно же, не буду.
Придумал реляционную теорию баз данных в 70-х годах XX столетия Эдгар Кодд, американский математик из IBM. Он положил в основу своей теории математическую модель, которая продолжает служить нам верой и правдой по сей день.
Однако при всех своих достоинствах данный тип хранилищ обладает рядом неприятных особенностей:
— реляционные базы плохо масштабируются, с ними крайне сложно создавать распределенные хранилища;
— проектирование крупных баз с множеством компонентов требует значительных усилий. Это приведение сущностей к нормальным формам и сложности в отображении связей типа многие-ко-многим. Такие схемы тяжело читать и понимать их бизнес-применение;
— эволюция схемы данных почти всегда отстает от новых потребностей бизнеса. Часто она успевает устаревать еще до выпуска новой фичи. Миграция на обновленную схему занимает безобразно долгие часы, в течение которых «сервер лежит».
Все эти сложности существуют по одной простой причине: реляционная модель была создана для хранения табличных данных. И для этих целей она прекрасно подходит. Но прошло уже почти полвека с момента изобретения модели реляций: за это время системы хранения данных давно успели вырасти из «простых табличек» в распределенных дата-монстров. Создавая свою теорию, господин Кодд явно не рассчитывал на такое.
Действие теоремы CAP в контексте SQL и NoSQL
В то время, как реляционные схемы полагаются на принципы ACID, все без исключения NoSQL хранилища опираются на другие принципы, описанные в теореме CAP. Для начала в ней утверждается, что любое хранилище данных имеет три базовых свойства:
— Согласованность данных (Consistency). То есть данные должны быть полными и непротиворечивыми (в том числе и во всех узлах кластера).
— Доступность (Availability). Грубо говоря, это скорость ответа сервера на наш запрос (для записи или чтения).
— Устойчивость к разделению (Partition tolerance). Это значит, что в случае разделения системы на несколько частей каждая из них, если она доступна, должна быть в состоянии работать автономно, отдавая корректный отклик и предоставляя свои данные. Обрыв связей в кластере не должен влиять на итоговую работу.
Теорема CAP сообщает нам, что из этих трёх компонентов мы можем получить только два. Либо в той же пропорции 2:1 балансировать между этими составляющими: улучшение характеристик по одному из свойств влечёт за собой ухудшение в каком-то другом. Чтобы лучше понять силу этой теоремы, представьте себе распределенное хранилище, в котором вы пытаетесь без тормозов по производительности обеспечить 100% согласованные данные (на чтение и запись).
В условиях работы односерверной архитектуры, если сервер работает, то он доступен. А база данных на нём, если руки проектировщика растут из плеч, — согласована. Беспокоиться об устойчивости к разделению узла нет никакой необходимости, так как система физически является неделимой. Именно в таких условиях возникли классические реляционные системы. И поэтому они неустойчивы к разделению: лишено смысла проектировать разделяемую структуру в неделимом окружении.
На самом деле, практически все NoSQL технологии были рождены с целью решить проблему устойчивости к разделению, то есть эффективно работать на кластерах. Реляционная модель не в состоянии справиться с этой задачей, так как была создана для других целей и в других условиях. У вас не получится «просто отпилить парочку-тройку таблиц или спокойно их партицировать в соседний кластер», а потом отправиться пить кофе-чай. Welcome to Hell.
Хранилища NoSQL по своей природе могут быть легко разделены на кластер из-за специфической структуры хранения данных.
Истинная суть теоремы CAP проявляется именно в условиях распределенной системы. Очевидно, что создавать неустойчивый к разделению кластер — лишено какой-либо практической пользы. То есть кластер априори должен создаваться устойчивым к разделению. Понимание этого факта позволяет нам увидеть теорему CAP в новом свете: из согласованности и доступности можно выбрать только что-то одно — или же использовать разумный компромисс между этими двумя пунктами (а не тремя, как можно подумать из оригинального определения).
Вторая задача, которую пытаются решить идеологи NoSQL технологий, — повышение доступности, то есть получать быстрый ответ сервера. За счет чего эта задача решается в агрегатных и графовых базах, я напишу в следующих статьях цикла.
Больше информации по этим вопросам можно найти, изучив понятие итоговой целостности и подхода BASE.
Общие свойства технологии NoSQL
Ниже я напишу о самых существенных на мой взгляд общих свойствах всех NoSQL технологий.
1. NoSQL противопоставляются реляционным базам (как можно догадаться из названия). Если подытожить всё сказанное выше в пояснениях к теореме CAP, то мы получим следующую картину. Условия существования баз данных изменились. В результате возникли новые проблемы, справиться с которыми классические SQL базы не могли. За короткий период времени родились целые семейства баз данных, целенаправленно отказавшихся от реляционной структуры. Мы получили ориентацию на кластеры, быстрый ответ сервера и итоговую целостность.
2. NoSQL имеют неявную схему данных — этот факт часто пугает инженеров, привыкших работать со строгой схемой реляционных баз. Я часто слышу аргументацию в стиле «в такую базу можно писать что угодно в любом порядке, это же хаос». На самом деле бардак можно устроить в любом месте, было бы желание. Но все данные, которые вы пишите, а потом читаете, имеют определенную структуру. У вас есть именованные поля, в них хранятся данные определенного типа. Проблема состоит лишь в том, что теперь контроль за вашей структурой перекладывается с СУБД на приложение: вы сами можете установить в нём любые правила валидаций.
Особый интерес вызывает ситуация, когда с базой работают сразу несколько приложений, каждое из которых хочет писать и читать неявно-структурированные данные. Очевидно, что рано или поздно между ними возникнет конфликт форматов. В этом случае можно поступить по-разному:
— разграничить зоны ответственности каждого приложения: в разные области схемы данных должны иметь доступ разные приложения;
— использовать идею шаблона Прокси: обернуть нашу драгоценность (базу) в отдельное приложение и общаться с ним через веб-сервисы.
Выделить проксирующий слой полезно и внутри одиночного приложения, таким образом вы получаете некоторую страховку от кривых рук джунов, норовящих производить запросы в базу напрямую.
Ещё одна отличительная особенность неявной схемы данных заключается в её эволюционности. Вы можете вносить коррективы в структуру данных на лету, в ногу с потребностями бизнеса. В реляционных базах менять архитектуру — всегда накладно. Это физически тяжело. Например, ALTER TABLE занимает 8,5 часов, при которых сервер базы недоступен. Но ты знаешь, что Mongo (документная база) или Vertica (семейство столбцов), или Neo4j (графовая база) могли бы решить эту задачу за 0,0000x сек. И это удручает в работе с SQL базами.
Дело в том, что изменение формата новых данных в NoSQL не требует обязательного исправления старых записей. Такие базы просто пишут новую информацию в нужном нам виде.
Однако обратная сторона этой медали заключается в том, что вам всё ещё нужно уметь читать и интерпретировать нужным образом ранее записанную информацию «устаревших» форматов. Что можно сделать, чтобы уменьшить боль неминуемого рефакторинга NoSQL баз:
— относиться серьезно к неявной схеме данных еще на моменте ее проектирования;
— покрывать тестами вашу неявную схему данных в базе, проверяя все нужные форматы содержимого;
— не надеяться, что отказ от старых форматов и миграция на новые будет легче, чем в реляционной модели: использование неявной схемы данных не избавляет вас от этой боли. Перепроектирование границ агрегата или создание новых узлов графа из атрибутов существующих узлов ничуть не лучше классического ALTER в базе SQL: вам всё равно придётся последовательно обходить значительную часть записей базы и исправлять их.
На этой оптимистичной ноте статья подходит к концу. В следующий раз мы рассмотрим особенности агрегатного семейства.
Сердечно благодарю Славу Конашкова за технические консультации и помощь в написании материала.
P.S. Очень доходчиво и подробно теорема CAP описана в книге «NoSql: новая методология разработки нереляционных баз данных» (Прамодкумар Дж. Садаладж, Мартин Фаулер). Подход BASE и сравнение технологий NoSQL также можно посмотреть в книге «Графовые базы данных» (Ян Робинсон, Джим Вебер, Эмиль Эифрем).
CAP Theorem FAQs
What is CAP Theorem?
Understanding the CAP theorem is simpler when you consider it piece by piece:
What is CAP theorem in distributed systems? A distributed network system stores data across multiple nodes—virtual or physical machines—simultaneously. It’s essential to understand the CAP theorem when designing a cloud application because all cloud apps are distributed systems.
What is CAP theorem consistency? Consistency of CAP theorem means that regardless of the node they connect to, all clients see the same data at once. For the write to one node to succeed, it must also instantly be replicated or forwarded to all the other nodes in the system.
CAP theorem eventual consistency. Some NoSQL databases (for example, ScyllaDB) use a model of tunable eventual consistency to deliver multi datacenter high availability and fast and efficient write and read operations. In this case, all nodes are equal; this means any node can serve any request, there is no single point of coordination, and all nodes in the system continue to cooperatively provide service, even when nodes become unavailable. Eventual consistency supports modern workloads that are less dependent on strong consistency but rely heavily on availability.
What is availability in CAP theorem? CAP theorem availability means that even if one or more nodes are down, any client making a data request receives a response. In other words, when any request is made, without exception, all working nodes in a distributed system return a valid response.
Partition tolerance in CAP theorem explained. In a distributed system, a partition is a break in communications—a temporarily delayed or lost connection between nodes. Partition tolerance means that in spite of any number of breakdowns in communication between nodes in the system, the cluster will continue to work.
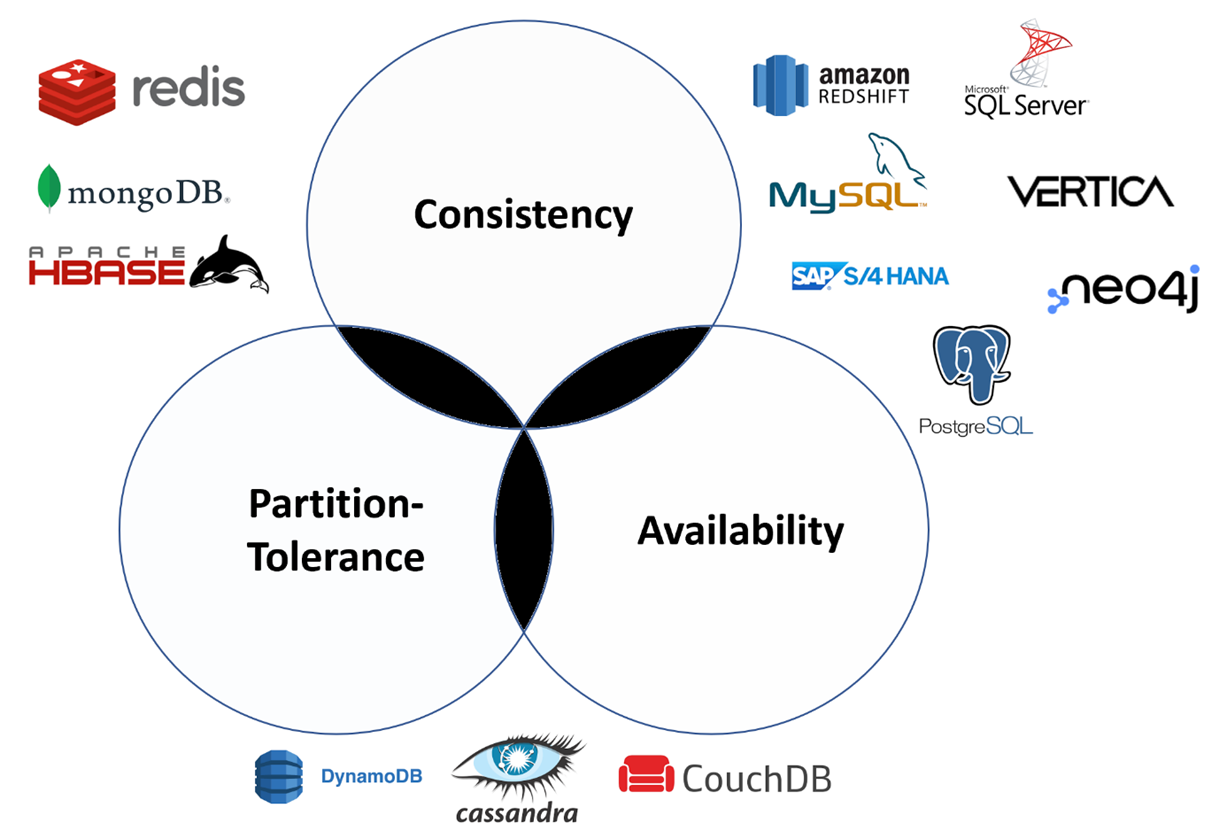
What is CAP theorem in NoSQL? NoSQL databases and CAP theorem are closely linked. NoSQL databases are categorized based on which CAP characteristics they support: CP, AP, or CA.
A CP database offers consistency and partition tolerance but sacrifices availability. The practical result is that when a partition occurs, the system must make the inconsistent node unavailable until it can resolve the partition. MongoDB and Redis are examples of CP databases.
An AP database provides availability and partition tolerance but not consistency in the event of a failure. All nodes remain available when a partition occurs, but some might return an older version of the data. CouchDB, Cassandra, and ScyllaDB are examples of AP databases.
A CA database delivers consistency and availability, but it can’t deliver fault tolerance if any two nodes in the system have a partition between them. Clearly, this is where CAP theorem and NoSQL databases collide: there are no NoSQL databases you would classify as CA under the CAP theorem. In a distributed database, there is no way to avoid system partitions. So, although CAP theorem stating a CA distributed database is possible exists, there is currently no true CA distributed database system. The modern goal of CAP theorem analysis should be for system designers to generate optimal combinations of consistency and availability for particular applications.
CAP Theorem vs ACID
Although the “C” in both ACID and CAP theorem refer to consistency, consistency in CAP is different than in ACID. In CAP, consistency means having information that is the most up-to-date. Consistency in ACID refers to the hardness of the database that protects it from corruption despite the addition of new transactions and references different database events.
Database systems such as RDBMS that are designed in part based on traditional ACID guarantees choose consistency over availability. In contrast, systems common in the NoSQL movement designed around the BASE philosophy select availability over consistency.
CAP Theorem NoSQL Database Examples
To better comprehend the role of CAP theorem in database theory, consider some CAP theorem databases examples.
MongoDB is a popular NoSQL database management system that is used for big data applications running across multiple locations. MongoDB resolves network partitions by maintaining consistency, sacrificing availability as necessary in the event of failure. One primary node receives all write operations in MongoDB. The system needs to elect a new primary node if the existing one becomes unavailable, and while it does, clients can’t make any write requests so data remains consistent.
In contrast to MongoDB, Apache Cassandra is an open source NoSQL database with a peer-to-peer architecture and potentially multiple points of failure. CAP theorem in Cassandra reveals an AP database: Cassandra offers availability and partition tolerance but can’t provide consistency all the time. However, by reconciling inconsistencies as quickly as possible and allowing clients to write to any nodes at any time, Cassandra provides eventual consistency. Inconsistencies are resolved quickly in most cases of network partitions, so the constant availability and high performance are often worth the Cassandra CAP theorem trade-off.
CAP Theorem in NoSQL Databases vs Distributed SQL Databases
NoSQL databases are generally considered to be AP systems, providing Availability and Partition tolerance at the expense of Consistency. In contrast, distributed SQL (NewSQL) databases provide Consistency, Availability and Partition tolerance. (According to Eric Brewer’s painstaking analysis, Google Spanner is technically a CP system that can claim to be an “effectively CA” system. Such nuances, while important, are beyond the scope of this glossary entry.)
The fusion of strong consistency with distributed architecture is undeniably attractive. The question is whether distributed SQL can deliver on this promise without compromising in other critical areas – primarily performance. Notably, the traditional CAP theorem makes no provision for performance or latency. For example, according to the CAP theorem, a database can be considered Available if a query returns a response after 30 days. Obviously, such latency would be unacceptable for any real-world application. Learn more from our educational page on SQL vs. NoSQL.
PACELC vs CAP Theorem
A newer way to model databases, the PACELC theorem, builds on the advantages of CAP theorem analysis and extends it, accounting for the nuances of modern systems. According to PACELC, Like the CAP theorem, the PACELC theorem states that in case of network partitioning (P) in a distributed computer system, one has to choose between availability (A) and consistency (C). PACELC extends the CAP theorem by introducing latency and consistency as additional attributes of distributed systems. The theorem states that, “else (E), even when the system is running normally in the absence of partitions, one has to choose between latency (L) and consistency (C).”
In other words, PACELC reveals that systems tend either towards strong consistency or latency sensitivity. Even in the absence of partitioning, a trade-off between consistency and latency exists.
Traditional CAP theorem provides for neither latency nor performance. For example, the CAP theorem considers a database available if a query returns a response after 30 days—a level of latency that users of any real-world application would find unacceptable.
Based on PACELC, a distributed SQL database that focuses on being a strongly consistent system such as CockroachDB is categorized as PC/EC. They will not sacrifice consistency for any reason, and performance may suffer as a result.
In contrast, a latency sensitive, highly available NoSQL database system like ScyllaDB is PA/EL. These systems may sacrifice consistency for availability should a partition occur.
Cloud-native applications with more modern, distributed architectures often demand predictable low latency and high availability. Strong consistency requirements are less common.
Does ScyllaDB Offer Solutions for CAP Theorem?
ScyllaDB is a PA/EL highly available, partition tolerant, low latency database system. ScyllaDB was designed to provide consistent low-latencies, not just be highly available, and it also provides tunable consistency. Under any conditions short of a complete system failure, ScyllaDB will remain highly available with predictable low latencies for mission critical applications.
ScyllaDB outperforms a distributed NewSQL database such as CockroachDB by a wide margin. Built for high availability, ScyllaDB still delivers tunable consistency, zero downtime, and high performance. Learn more.
Understanding databases for storing, updating and analyzing data requires the understanding of the CAP Theorem. This is the second article of the article series Data Warehousing Basics.
Understanding NoSQL Databases by the CAP Theorem
CAP theorem – or Brewer’s theorem – was introduced by the computer scientist Eric Brewer at Symposium on Principles of Distributed computing in 2000. The CAP stands for Consistency, Availability and Partition tolerance.
- Consistency: Every read receives the most recent writes or an error. Once a client writes a value to any server and gets a response, it is expected to get afresh and valid value back from any server or node of the database cluster it reads from.
Be aware that the definition of consistency for CAP means something different than to ACID (relational consistency). - Availability: The database is not allowed to be unavailable because it is busy with requests. Every request received by a non-failing node in the system must result in a response. Whether you want to read or write you will get some response back. If the server has not crashed, it is not allowed to ignore the client’s requests.
- Partition tolerance: Databases which store big data will use a cluster of nodes that distribute the connections evenly over the whole cluster. If this system has partition tolerance, it will continue to operate despite a number of messages being delayed or even lost by the network between the cluster nodes.
CAP theorem applies the logic that for a distributed system it is only possible to simultaneously provide two out of the above three guarantees. Eric Brewer, the father of the CAP theorem, proved that we are limited to two of three characteristics, “by explicitly handling partitions, designers can optimize consistency and availability, thereby achieving some trade-off of all three.” (Brewer, E., 2012).
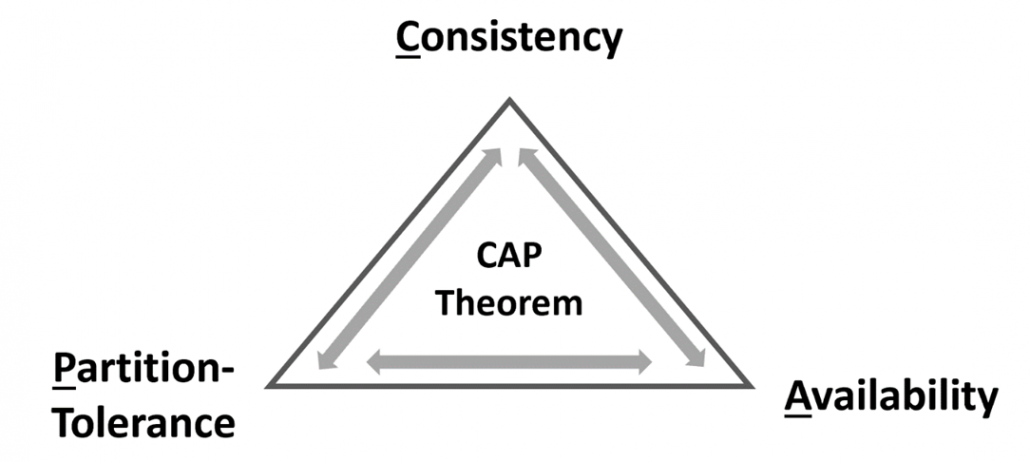
To recap, with the CAP theorem in relation to Big Data distributed solutions (such as NoSQL databases), it is important to reiterate the fact, that in such distributed systems it is not possible to guarantee all three characteristics (Availability, Consistency, and Partition Tolerance) at the same time.
Database systems designed to fulfill traditional ACID guarantees like relational database (management) systems (RDBMS) choose consistency over availability, whereas NoSQL databases are mostly systems designed referring to the BASE philosophy which prefer availability over consistency.
The CAP Theorem in the real world
Lets look at some examples to understand the CAP Theorem further and provewe cannot create database systems which are being consistent, partition tolerant as well as always available simultaniously.
AP – Availability + Partition Tolerance
If we have achieved Availability (our databases will always respond to our requests) as well as Partition Tolerance (all nodes of the database will work even if they cannot communicate), it will immediately mean that we cannot provide Consistency as all nodes will go out of sync as soon as we write new information to one of the nodes. The nodes will continue to accept the database transactions each separately, but they cannot transfer the transaction between each other keeping them in synchronization. We therefore cannot fully guarantee the system consistency. When the partition is resolved, the AP databases typically resync the nodes to repair all inconsistencies in the system.
A well-known real world example of an AP system is the Domain Name System (DNS). This central network component is responsible for resolving domain names into IP addresses and focuses on the two properties of availability and failure tolerance. Thanks to the large number of servers, the system is available almost without exception. If a single DNS server fails,another one takes over. According to the CAP theorem, DNS is not consistent: If a DNS entry is changed, e.g. when a new domain has been registered or deleted, it can take a few days before this change is passed on to the entire system hierarchy and can be seen by all clients.
CA – Consistency + Availability
Guarantee of full Consistency and Availability is practically impossible to achieve in a system which distributes data over several nodes. We can have databases over more than one node online and available, and we keep the data consistent between these nodes, but the nature of computer networks (LAN, WAN) is that the connection can get interrupted, meaning we cannot guarantee the Partition Tolerance and therefor not the reliability of having the whole database service online at all times.
Database management systems based on the relational database models (RDBMS) are a good example of CA systems. These database systems are primarily characterized by a high level of consistency and strive for the highest possible availability. In case of doubt, however, availability can decrease in favor of consistency. Reliability by distributing data over partitions in order to make data reachable in any case – even if computer or network failure – meanwhile plays a subordinate role.
CP – Consistency + Partition Tolerance
If the Consistency of data is given – which means that the data between two or more nodes always contain the up-to-date information – and Partition Tolerance is given as well – which means that we are avoiding any desynchronization of our data between all nodes, then we will lose Availability as soon as only one a partition occurs between any two nodes In most distributed systems, high availability is one of the most important properties, which is why CP systems tend to be a rarity in practice. These systems prove their worth particularly in the financial sector: banking applications that must reliably debit and transfer amounts of money on the account side are dependent on consistency and reliability by consistent redundancies to always be able to rule out incorrect postings – even in the event of disruptions in the data traffic. If consistency and reliability is not guaranteed, the system might be unavailable for the users.
Conclusion
The CAP Theorem is still an important topic to understand for data engineers and data scientists, but many modern databases enable us to switch between the possibilities within the CAP Theorem. For example, the Cosmos DB von Microsoft Azure offers many granular options to switch between the consistency, availability and partition tolerance . A common misunderstanding of the CAP theorem that it´s none-absoluteness: “All three properties are more continuous than binary. Availability is continuous from 0 to 100 percent, there are many levels of consistency, and even partitions have nuances. Exploring these nuances requires pushing the traditional way of dealing with partitions, which is the fundamental challenge. Because partitions are rare, CAP should allow perfect C and A most of the time, but when partitions are present or perceived, a strategy is in order.” (Brewer, E., 2012).
About Author

Benjamin Aunkofer
Benjamin Aunkofer is Lead Data Scientist at DATANOMIQ, a consulting company for applied data science in Berlin. He is lecturer for Data Science and Data Strategy at HTW Berlin and gives trainings for Business Intelligence, Data Science and Machine Learning for companies.