From Wikipedia, the free encyclopedia
In mathematical folklore, the «no free lunch» (NFL) theorem (sometimes pluralized) of David Wolpert and William Macready appears in the 1997 «No Free Lunch Theorems for Optimization».[1] Wolpert had previously derived no free lunch theorems for machine learning (statistical inference).[2] The name alludes to the saying «there ain’t no such thing as a free lunch», that is, there are no easy shortcuts to success.
In 2005, Wolpert and Macready themselves indicated that the first theorem in their paper «state[s] that any two optimization algorithms are equivalent when their performance is averaged across all possible problems».[3]
The «no free lunch» (NFL) theorem is an easily stated and easily understood consequence of theorems Wolpert and Macready actually prove. It is weaker than the proven theorems, and thus does not encapsulate them. Various investigators have extended the work of Wolpert and Macready substantively. In terms of how the NFL theorem is used in the context of the research area, the no free lunch in search and optimization is a field that is dedicated for purposes of mathematically analyzing data for statistical identity, particularly search[4] and optimization.[5]
While some scholars argue that NFL conveys important insight, others argue that NFL is of little relevance to machine learning research.[6][7]
Example[edit]
Posit a toy universe that exists for exactly two days and on each day contains exactly one object, a square or a triangle. The universe has exactly four possible histories:
- (square, triangle): the universe contains a square on day 1, and a triangle on day 2
- (square, square)
- (triangle, triangle)
- (triangle, square)
Any prediction strategy that succeeds for history #2, by predicting a square on day 2 if there is a square on day 1, will fail on history #1, and vice versa. If all histories are equally likely, then any prediction strategy will score the same, with the same accuracy rate of 0.5.[8]
Origin[edit]
Wolpert and Macready give two NFL theorems that are closely related to the folkloric theorem. In their paper, they state:
We have dubbed the associated results NFL theorems because they demonstrate that if an algorithm performs well on a certain class of problems then it necessarily pays for that with degraded performance on the set of all remaining problems.[5]
The first theorem hypothesizes objective functions that do not change while optimization is in progress, and the second hypothesizes objective functions that may change.[5]
Theorem 1: For any algorithms a1 and a2, at iteration step m

where  denotes the ordered set of size
denotes the ordered set of size  of the cost values
of the cost values  associated to input values
associated to input values  ,
,  is the function being optimized and
is the function being optimized and  is the conditional probability of obtaining a given sequence of cost values from algorithm
is the conditional probability of obtaining a given sequence of cost values from algorithm  run times on function
run times on function  .
.
The theorem can be equivalently formulated as follows:
Theorem 1: Given a finite set  and a finite set
and a finite set  of real numbers, assume that
of real numbers, assume that  is chosen at random according to uniform distribution on the set
is chosen at random according to uniform distribution on the set  of all possible functions from to . For the problem of optimizing over the set , then no algorithm performs better than blind search.
of all possible functions from to . For the problem of optimizing over the set , then no algorithm performs better than blind search.
Here, blind search means that at each step of the algorithm, the element  is chosen at random with uniform probability distribution from the elements of that have not been chosen previously.
is chosen at random with uniform probability distribution from the elements of that have not been chosen previously.
In essence, this says that when all functions f are equally likely, the probability of observing an arbitrary sequence of m values in the course of optimization does not depend upon the algorithm. In the analytic framework of Wolpert and Macready, performance is a function of the sequence of observed values (and not e.g. of wall-clock time), so it follows easily that all algorithms have identically distributed performance when objective functions are drawn uniformly at random, and also that all algorithms have identical mean performance. But identical mean performance of all algorithms does not imply Theorem 1, and thus the folkloric theorem is not equivalent to the original theorem.
Theorem 2 establishes a similar, but «more subtle», NFL result for time-varying objective functions.[5]
Motivation[edit]
The NFL theorems were explicitly not motivated by the question of what can be inferred (in the case of NFL for machine learning) or found (in the case of NFL for search) when the «environment is uniform random». Rather uniform randomness was used as a tool, to compare the number of environments for which algorithm A outperforms algorithm B to the number of environments for which B outperforms A. NFL tells us that (appropriately weighted)[clarification needed] there are just as many environments in both of those sets.
This is true for many definitions of what precisely an «environment» is. In particular, there are just as many prior distributions (appropriately weighted) in which learning algorithm A beats B (on average) as vice versa.[citation needed] This statement about sets of priors is what is most important about NFL, not the fact that any two algorithms perform equally for the single, specific prior distribution that assigns equal probability to all environments.
While the NFL is important to understand the fundamental limitation for a set of problems, it does not state anything about each particular instance of a problem that can arise in practice. That is, the NFL states what is contained in its mathematical statements and it is nothing more than that. For example, it applies to the situations where the algorithm is fixed a priori and a worst-case problem for the fixed algorithm is chosen a posteriori. Therefore, if we have a «good» problem in practice or if we can choose a «good» learning algorithm for a given particular problem instance, then the NFL does not mention any limitation about this particular problem instance. Though the NFL might seem contradictory to results from other papers suggesting generalization of learning algorithms or search heuristics, it is important to understand the difference between the exact mathematical logic of the NFL and its intuitive interpretation.[9]
Implications[edit]
To illustrate one of the counter-intuitive implications of NFL, suppose we fix two supervised learning algorithms, C and D. We then sample a target function f to produce a set of input-output pairs, d. How should we choose whether to train C or D on d, in order to make predictions for what output would be associated with a point lying outside of d?
It is common in almost all of science and statistics to answer this question – to choose between C and D – by running cross-validation on d with those two algorithms. In other words, to decide whether to generalize from d with either C or D, we see which of them has better out-of-sample performance when tested within d.
Since C and D are fixed, this use of cross-validation to choose between them is itself an algorithm, i.e., a way of generalizing from an arbitrary dataset. Call this algorithm A. (Arguably, A is a simplified model of the scientific method itself.)
We could also use anti-cross-validation to make our choice. In other words, we could choose between C and D based on which has worse out-of-sample performance within d. Again, since C and D are fixed, this use of anti-cross-validation is itself an algorithm. Call that algorithm B.
NFL tells us (loosely speaking) that B must beat A on just as many target functions (and associated datasets d) as A beats B. In this very specific sense, the scientific method will lose to the «anti» scientific method just as readily as it wins.[10]
NFL only applies if the target function is chosen from a uniform distribution of all possible functions. If this is not the case, and certain target functions are more likely to be chosen than others, then A may perform better than B overall. The contribution of NFL is that it tells us choosing an appropriate algorithm requires making assumptions about the kinds of target functions the algorithm is being used for. With no assumptions, no «meta-algorithm», such as the scientific method, performs better than random choice.
While some scholars argue that NFL conveys important insight, others argue that NFL is of little relevance to machine learning research.[6][7] If Occam’s razor is correct, for example if sequences of lower Kolmogorov complexity are more probable than sequences of higher complexity, then (as is observed in real life) some algorithms, such as cross-validation, perform better on average on practical problems (when compared with random choice or with anti-cross-validation).[11]
Notes[edit]
- ^ Wolpert, D.H., Macready, W.G. (1997), «No Free Lunch Theorems for Optimization», IEEE Transactions on Evolutionary Computation 1, 67.
- ^ Wolpert, David (1996), «The Lack of A Priori Distinctions between Learning Algorithms», Neural Computation, pp. 1341–1390. Archived 2016-12-20 at the Wayback Machine
- ^ Wolpert, D.H., and Macready, W.G. (2005) «Coevolutionary free lunches», IEEE Transactions on Evolutionary Computation, 9(6): 721–735
- ^ Wolpert, D. H.; Macready, W. G. (1995). «No Free Lunch Theorems for Search» (PDF). Technical Report SFI-TR-95-02-010. Santa Fe Institute. S2CID 12890367.
- ^ a b c d Wolpert, D. H.; Macready, W. G. (1997). «No Free Lunch Theorems for Optimization». IEEE Transactions on Evolutionary Computation. 1: 67–82. doi:10.1109/4235.585893. S2CID 5553697.
- ^ a b Whitley, Darrell, and Jean Paul Watson. «Complexity theory and the no free lunch theorem.» In Search Methodologies, pp. 317–339. Springer, Boston, MA, 2005.
- ^ a b Giraud-Carrier, Christophe, and Foster Provost. «Toward a justification of meta-learning: Is the no free lunch theorem a show-stopper.» In Proceedings of the ICML-2005 Workshop on Meta-learning, pp. 12–19. 2005.
- ^ Forster, Malcolm R. (1999). «How do Simple Rules ‘Fit to Reality’ in a Complex World?». Minds and Machines. 9 (4): 543–564. doi:10.1023/A:1008304819398. S2CID 8802657.
- ^ Kawaguchi, K., Kaelbling, L.P, and Bengio, Y.(2017) «Generalization in deep learning», https://arxiv.org/abs/1710.05468
- ^ Wolpert, D.H. (2013) «What the no free lunch theorems really mean», Ubiquity, Volume 2013, December 2013, doi:10.1145/2555235.2555237
- ^ Lattimore, Tor, and Marcus Hutter. «No free lunch versus Occam’s razor in supervised learning.» In Algorithmic Probability and Friends. Bayesian Prediction and Artificial Intelligence, pp. 223–235. Springer, Berlin, Heidelberg, 2013.
External links[edit]
- No Free Lunch Theorems
- Graphics illustrating the theorem
1.9. No Free Lunch теорема
Возникает естественный вопрос – существует ли некоторый лучший эволюционный алгоритм, который дает всегда лучшие результаты при решении всевозможных проблем? Например, можно ли выбрать генетические операторы и их параметры так, чтобы алгоритм давал лучшие результаты независимо от решаемой проблемы? К сожалению, ответ отрицательный – такого лучшего эволюционного алгоритма не существует! Это следует из известной No Free Lunch (NFL) теоремы (бесплатных завтраков не бывает), которая доказана относительно недавно, в 1996г.[18,19] и вызвала оживленную дискуссию. Пусть 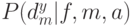 — условная вероятность получения частного решения
— условная вероятность получения частного решения 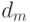 после
после  итераций работы алгоритма
итераций работы алгоритма  при целевой функции
при целевой функции  . В этих терминах Вольперт и Макреди доказали так называемую No Free Lunch (NFL) теорему:
. В этих терминах Вольперт и Макреди доказали так называемую No Free Lunch (NFL) теорему:
NFL теорема. Для любой пары алгоритмов 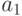 и
и  имеет место равенство
имеет место равенство

Таким образом, сумма условных вероятностей посещения в пространстве решений каждой точки одинакова для множества всевозможных целевых функций независимо от используемого алгоритма. Из этого результата непосредственно следует, что при любой мере 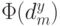 производительности (характеристик сложности) алгоритма в среднем для всевозможных целевых функций вероятность
производительности (характеристик сложности) алгоритма в среднем для всевозможных целевых функций вероятность 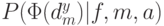 не зависит от алгоритма . Другими словами, не существует лучшего алгоритма (эволюционного или любого другого) для решения всех проблем. Если алгоритм выигрывает по своим характеристикам при решении некоторого класса задач, то это неминуемо компенсируется проигрышем (худшими характеристиками) для остальных задач.
не зависит от алгоритма . Другими словами, не существует лучшего алгоритма (эволюционного или любого другого) для решения всех проблем. Если алгоритм выигрывает по своим характеристикам при решении некоторого класса задач, то это неминуемо компенсируется проигрышем (худшими характеристиками) для остальных задач.
Эта теорема вызвала оживленную дискуссию у специалистов по эволюционным вычислениям и некоторое неприятие. Дело в том, что в семидесятых годах были предприняты значительные усилия по поиску лучших значений параметров и генетических операторов ГА. Исследовались различные генетические операторы, значения вероятностей выполнения кроссинговера и мутации, мощности популяции и т.д. Большинство этих исследований апробировалось на сложившихся в каждой проблемной области тестовых задачах. Но из NFL-теоремы следует, что полученные результаты справедливы только на использованных тестовых задачах, а не для произвольных задач. Все усилия найти лучший оператор кроссинговера или мутации, оптимальные значения их параметров при отсутствии ограничений для исследуемого класса задач не имеют смысла!
Каждому эволюционному алгоритму присуще некоторое представление, которое позволяет манипулировать с потенциальными решениями. NFL теорема утверждает, что не существует лучшего эволюционного алгоритма для решения всех проблем.
Для того чтобы разрабатываемый алгоритм решал поставленную задачу лучше, чем случайный поиск (который с точки зрения NFL теоремы является просто другим алгоритмом) необходимо в нем использовать (отразить) структуру (априорные знания) этой проблемы. Из этого следует, что такой алгоритм может не соответствовать структуре другой проблемы (и покажет для нее плохие результаты). Следует отметить, что недостаточно просто указать, что проблема имеет некоторую структуру — такая структура должна соответствовать разрабатываемому алгоритму. Более того, структура должна быть определена. Недостаточно, как это иногда бывает, сказать «Мы имеем дело с реальными проблемами, а не с всевозможными, поэтому NFL теорема не применима». Что значит структура реальной проблемы? Очевидно, что формальное описание такой структуры проблематично. Например, реальные проблемы нашего времени и столетней давности могут сильно отличаться. Следует отметить, что простое сужение области возможных проблем без идентификации соответствия между рассматриваемым множеством проблем и алгоритмом недостаточно для получения преимущества данного метода решения этих проблем по сравнению с другими.
NFL-теорема подтверждает, что разные алгоритмы имеют различную эффективность при решении разных задач. Например, классические методы оптимизации, как правило, более эффективны при решении линейных, квадратичных, строго выпуклых, унимодальных, разделяемых и других специальных классов проблем. С другой стороны, генетические алгоритмы часто успешно решают задачи там, где классические методы не работают – там, где целевые функции терпят разрывы, не дифференцируемы, мультимодальны (имеют много экстремумов), зашумлены и т.п. Обычно их эффективность и устойчивость выше там, где целевые функции имеют сложный (не стандартный) вид, что более характерно для решения реальных практических задач. Конечно, лучшим способом подтверждения эффективности алгоритма является доказательство его сходимости и оценки вычислительной сложности. Но, как правило, это возможно только в случае упрощенной постановки задачи. Другой альтернативой является проверка алгоритмов на тестовых задачах (benchmarks) данной проблемной области. К сожалению, в настоящее время не существует согласованного каталога таких задач для оценки старых или новых алгоритмов решения, хотя для многих типовых задач они уже сложились и широко используются.
From Wikipedia, the free encyclopedia
This article is about mathematical analysis of computing. For associated folklore and broad implications of the theorem, see No free lunch theorem.
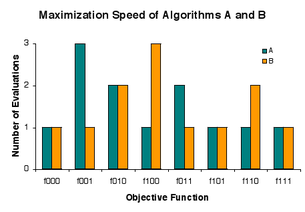
The problem is to rapidly find a solution among candidates a, b, and c that is as good as any other, where goodness is either 0 or 1. There are eight instances («lunch plates») fxyz of the problem, where x, y, and z indicate the goodness of a, b, and c, respectively. Procedure («restaurant») A evaluates candidates in the order a, b, c, and B evaluates candidates in reverse that order, but each «charges» 1 evaluation in 5 cases, 2 evaluations in 2 cases, and 3 evaluations in 1 case.
In computational complexity and optimization the no free lunch theorem is a result that states that for certain types of mathematical problems, the computational cost of finding a solution, averaged over all problems in the class, is the same for any solution method. The name alludes to the saying «there ain’t no such thing as a free lunch», that is, no method offers a «short cut». This is under the assumption that the search space is a probability density function. It does not apply to the case where the search space has underlying structure (e.g., is a differentiable function) that can be exploited more efficiently (e.g., Newton’s method in optimization) than random search or even has closed-form solutions (e.g., the extrema of a quadratic polynomial) that can be determined without search at all. For such probabilistic assumptions, the outputs of all procedures solving a particular type of problem are statistically identical. A colourful way of describing such a circumstance, introduced by David Wolpert and William G. Macready in connection with the problems of search[1]
and optimization,[2]
is to say that there is no free lunch. Wolpert had previously derived no free lunch theorems for machine learning (statistical inference).[3]
Before Wolpert’s article was published, Cullen Schaffer independently proved a restricted version of one of Wolpert’s theorems and used it to critique the current state of machine learning research on the problem of induction.[4]
In the «no free lunch» metaphor, each «restaurant» (problem-solving procedure) has a «menu» associating each «lunch plate» (problem) with a «price» (the performance of the procedure in solving the problem). The menus of restaurants are identical except in one regard – the prices are shuffled from one restaurant to the next. For an omnivore who is as likely to order each plate as any other, the average cost of lunch does not depend on the choice of restaurant. But a vegan who goes to lunch regularly with a carnivore who seeks economy might pay a high average cost for lunch. To methodically reduce the average cost, one must use advance knowledge of a) what one will order and b) what the order will cost at various restaurants. That is, improvement of performance in problem-solving hinges on using prior information to match procedures to problems.[2][4]
In formal terms, there is no free lunch when the probability distribution on problem instances is such that all problem solvers have identically distributed results. In the case of search, a problem instance in this context is a particular objective function, and a result is a sequence of values obtained in evaluation of candidate solutions in the domain of the function. For typical interpretations of results, search is an optimization process. There is no free lunch in search if and only if the distribution on objective functions is invariant under permutation of the space of candidate solutions.[5][6][7] This condition does not hold precisely in practice,[6] but an «(almost) no free lunch» theorem suggests that it holds approximately.[8]
Overview[edit]
Some computational problems are solved by searching for good solutions in a space of candidate solutions. A description of how to repeatedly select candidate solutions for evaluation is called a search algorithm. On a particular problem, different search algorithms may obtain different results, but over all problems, they are indistinguishable. It follows that if an algorithm achieves superior results on some problems, it must pay with inferiority on other problems. In this sense there is no free lunch in search.[1] Alternatively, following Schaffer,[4] search performance is conserved. Usually search is interpreted as optimization, and this leads to the observation that there is no free lunch in optimization.[2]
«The ‘no free lunch’ theorem of Wolpert and Macready,» as stated in plain language by Wolpert and Macready themselves, is that «any two algorithms are equivalent when their performance is averaged across all possible problems.»[9] The «no free lunch» results indicate that matching algorithms to problems gives higher average performance than does applying a fixed algorithm to all.[citation needed] Igel and Toussaint[6] and English[7] have established a general condition under which there is no free lunch. While it is physically possible, it does not hold precisely.[6] Droste, Jansen, and Wegener have proved a theorem they interpret as indicating that there is «(almost) no free lunch» in practice.[8]
To make matters more concrete, consider an optimization practitioner confronted with a problem. Given some knowledge of how the problem arose, the practitioner may be able to exploit the knowledge in selection of an algorithm that will perform well in solving the problem. If the practitioner does not understand how to exploit the knowledge, or simply has no knowledge, then he or she faces the question of whether some algorithm generally outperforms others on real-world problems. The authors of the «(almost) no free lunch» theorem say that the answer is essentially no, but admit some reservations as to whether the theorem addresses practice.[8]
Theorems[edit]
A «problem» is, more formally, an objective function that associates candidate solutions with goodness values. A search algorithm takes an objective function as input and evaluates candidate solutions one-by-one. The output of the algorithm is the sequence of observed goodness values.[10][11]
Wolpert and Macready stipulate that an algorithm never reevaluates a candidate solution, and that algorithm performance is measured on outputs.[2] For simplicity, we disallow randomness in algorithms. Under these conditions, when a search algorithm is run on every possible input, it generates each possible output exactly once.[7] Because performance is measured on the outputs, the algorithms are indistinguishable in how often they achieve particular levels of performance.
Some measures of performance indicate how well search algorithms do at optimization of the objective function. Indeed, there seems to be no interesting application of search algorithms in the class under consideration but to optimization problems. A common performance measure is the least index of the least value in the output sequence. This is the number of evaluations required to minimize the objective function. For some algorithms, the time required to find the minimum is proportional to the number of evaluations.[7]
The original no free lunch (NFL) theorems assume that all objective functions are equally likely to be input to search algorithms.[2] It has since been established that there is NFL if and only if, loosely speaking, «shuffling» objective functions has no impact on their probabilities.[6][7] Although this condition for NFL is physically possible, it has been argued that it certainly does not hold precisely.[6]
The obvious interpretation of «not NFL» is «free lunch,» but this is misleading. NFL is a matter of degree, not an all-or-nothing proposition. If the condition for NFL holds approximately, then all algorithms yield approximately the same results over all objective functions.[7] «Not NFL» implies only that algorithms are inequivalent overall by some measure of performance. For a performance measure of interest, algorithms may remain equivalent, or nearly so.[7]
Kolmogorov randomness[edit]
Almost all elements of the set of all possible functions (in the set-theoretic sense of «function») are Kolmogorov random, and hence the NFL theorems apply to a set of functions almost all of which cannot be expressed more compactly than as a lookup table that contains a distinct (and random) entry for each point in the search space. Functions that can be expressed more compactly (for example, by a mathematical expression of reasonable size) are by definition not Kolmogorov random.
Further, within the set of all possible objective functions, levels of goodness are equally represented among candidate solutions, hence good solutions are scattered throughout the space of candidates. Accordingly, a search algorithm will rarely evaluate more than a small fraction of the candidates before locating a very good solution.[11]
Almost all objective functions are of such high Kolmogorov complexity that they cannot be stored in a particular computer.[5][7][11] More precisely, if we model a given physical computer as a register machine with a given size memory on the order of the memories of modern computers, then most objective functions cannot be stored in their memories. There is more information in the typical objective function or algorithm than Seth Lloyd estimates the observable universe is capable of registering.[12] For instance, if each candidate solution is encoded as a sequence of 300 0’s and 1’s, and the goodness values are 0 and 1, then most objective functions have Kolmogorov complexity of at least 2300 bits,[13] and this is greater than Lloyd’s bound of 1090 ≈ 2299 bits. It follows that the original «no free lunch» theorem does not apply to what can be stored in a physical computer; instead the so-called «tightened» no free lunch theorems need to be applied. It has also been shown that NFL results apply to incomputable functions.[14]
Formal synopsis[edit]
 is the set of all objective functions f:X→Y, where
is the set of all objective functions f:X→Y, where  is a finite solution space and
is a finite solution space and  is a finite poset. The set of all permutations of X is J. A random variable F is distributed on . For all j in J, F o j is a random variable distributed on , with P(F o j = f) = P(F = f o j−1) for all f in .
is a finite poset. The set of all permutations of X is J. A random variable F is distributed on . For all j in J, F o j is a random variable distributed on , with P(F o j = f) = P(F = f o j−1) for all f in .
Let a(f) denote the output of search algorithm a on input f. If a(F) and b(F) are identically distributed for all search algorithms a and b, then F has an NFL distribution. This condition holds if and only if F and F o j are identically distributed for all j in J.[6][7] In other words, there is no free lunch for search algorithms if and only if the distribution of objective functions is invariant under permutation of the solution space.[15] Set-theoretic NFL theorems have recently been generalized to arbitrary cardinality and .[16]
Origin[edit]
Wolpert and Macready give two principal NFL theorems, the first regarding objective functions that do not change while search is in progress, and the second regarding objective functions that may change.[2]
- Theorem 1: For any pair of algorithms a1 and a2
 where denotes the ordered set of size of the cost values associated to input values , is the function being optimized and is the conditional probability of obtaining a given sequence of cost values from algorithm run times on function .
where denotes the ordered set of size of the cost values associated to input values , is the function being optimized and is the conditional probability of obtaining a given sequence of cost values from algorithm run times on function .



In essence, this says that when all functions f are equally likely, the probability of observing an arbitrary sequence of m values in the course of search does not depend upon the search algorithm.
The second theorem establishes a «more subtle» NFL result for time-varying objective functions.[2]
Interpretations of results[edit]
A conventional, but not entirely accurate, interpretation of the NFL results is that «a general-purpose universal optimization strategy is theoretically impossible, and the only way one strategy can outperform another is if it is specialized to the specific problem under consideration».[17] Several comments are in order:
- A general-purpose almost-universal optimizer exists theoretically. Each search algorithm performs well on almost all objective functions.[11] So if one is not concerned with the «relatively small» differences between search algorithms, e.g., because computer time is cheap, then you shouldn’t worry about no free lunch.
- An algorithm may outperform another on a problem when neither is specialized to the problem. Indeed, it may be that both algorithms are among the worst for the problem. More generally, Wolpert and Macready have developed a measure of the degree of «alignment» between an algorithm and a distribution over problems (strictly speaking, an inner product).[2] To say that one algorithm matches a distribution better than another is not to say that either has been consciously specialized to the distribution; an algorithm may have good alignment just by luck.
- In practice, some algorithms reevaluate candidate solutions. The reason to only consider performance on never-before-evaluated candidates is to make sure that in comparing algorithms one is comparing apples to apples. Moreover, any superiority of an algorithm that never reevaluates candidates over another algorithm that does on a particular problem may have nothing to do with specialization to the problem.
- For almost all objective functions, specialization is essentially accidental. Incompressible, or Kolmogorov random, objective functions have no regularity for an algorithm to exploit, as far as the universal Turing machining used to define Kolmogorov randomness is concerned. So presume that there is one, clearly superior choice of universal Turing machine. Then given an objective function that is incompressible for that Turing machine, there is no basis for choosing between two algorithms if both are compressible, as measured using that Turing machine. If a chosen algorithm performs better than most, the result is happenstance.[11] A Kolmogorov random function has no representation smaller than a lookup table that contains a (random) value corresponding to each point in the search space; any function that can be expressed more compactly is, by definition, not Kolmogorov random.
In practice, only highly compressible (far from random) objective functions fit in the storage of computers, and it is not the case that each algorithm performs well on almost all compressible functions. There is generally a performance advantage in incorporating prior knowledge of the problem into the algorithm. While the NFL results constitute, in a strict sense, full employment theorems for optimization professionals, it is important to bear the larger context in mind. For one thing, humans often have little prior knowledge to work with. For another, incorporating prior knowledge does not give much of a performance gain on some problems. Finally, human time is very expensive relative to computer time. There are many cases in which a company would choose to optimize a function slowly with an unmodified computer program rather than rapidly with a human-modified program.
The NFL results do not indicate that it is futile to take «pot shots» at problems with unspecialized algorithms. No one has determined the fraction of practical problems for which an algorithm yields good results rapidly. And there is a practical free lunch, not at all in conflict with theory. Running an implementation of an algorithm on a computer costs very little relative to the cost of human time and the benefit of a good solution. If an algorithm succeeds in finding a satisfactory solution in an acceptable amount of time, a small investment has yielded a big payoff. If the algorithm fails, then little is lost.
Coevolution[edit]
Wolpert and Macready have proved that there are free lunches in coevolutionary optimization.[9] Their analysis «covers ‘self-play’ problems. In these problems, the set of players work together to produce a champion, who then engages one or more antagonists in a subsequent multiplayer game.»[9] That is, the objective is to obtain a good player, but without an objective function. The goodness of each player (candidate solution) is assessed by observing how well it plays against others. An algorithm attempts to use players and their quality of play to obtain better players. The player deemed best of all by the algorithm is the champion. Wolpert and Macready have demonstrated that some coevolutionary algorithms are generally superior to other algorithms in quality of champions obtained. Generating a champion through self-play is of interest in evolutionary computation and game theory. The results are inapplicable to coevolution of biological species, which does not yield champions.[9]
See also[edit]
- Evolutionary informatics
- Inductive bias
- Occam’s razor
- Simplicity
- Ugly duckling theorem
Notes[edit]
- ^ a b Wolpert, D. H.; Macready, W. G. (1995). «No Free Lunch Theorems for Search» (PDF). Technical Report SFI-TR-95-02-010. Santa Fe Institute. S2CID 12890367.
- ^ a b c d e f g h Wolpert, D. H.; Macready, W. G. (1997). «No Free Lunch Theorems for Optimization». IEEE Transactions on Evolutionary Computation. 1: 67–82. doi:10.1109/4235.585893. S2CID 5553697.
- ^ Wolpert, David (1996). «The Lack of A Priori Distinctions between Learning Algorithms» (PDF). Neural Computation. Vol. 8. pp. 1341–1390. doi:10.1162/neco.1996.8.7.1341. S2CID 207609360.
- ^ a b c Schaffer, Cullen (1994). «A conservation law for generalization performance» (PDF). In Willian, H.; Cohen, W. (eds.). International Conference on Machine Learning. San Francisco: Morgan Kaufmann. pp. 259–265.
- ^ a b Streeter, M. (2003) «Two Broad Classes of Functions for Which a No Free Lunch Result Does Not Hold,» Genetic and Evolutionary Computation – GECCO 2003, pp. 1418–1430.
- ^ a b c d e f g Igel, C., and Toussaint, M. (2004) «A No-Free-Lunch Theorem for Non-Uniform Distributions of Target Functions,» Journal of Mathematical Modelling and Algorithms 3, pp. 313–322.
- ^ a b c d e f g h i English, T. (2004) No More Lunch: Analysis of Sequential Search, Proceedings of the 2004 IEEE Congress on Evolutionary Computation, pp. 227–234.
- ^ a b c S. Droste, T. Jansen, and I. Wegener. 2002. «Optimization with randomized search heuristics: the (A)NFL theorem, realistic scenarios, and difficult functions,» Theoretical Computer Science, vol. 287, no. 1, pp. 131–144.
- ^ a b c d Wolpert, D.H., and Macready, W.G. (2005) «Coevolutionary free lunches,» IEEE Transactions on Evolutionary Computation, 9(6): 721–735
- ^ A search algorithm also outputs the sequence of candidate solutions evaluated, but that output is unused in this article.
- ^ a b c d e English, T. M. (2000). «Optimization Is Easy and Learning Is Hard in the Typical Function». Proceedings of the 2000 Congress on Evolutionary Computation: CEC00. 2: 924–931. doi:10.1109/CEC.2000.870741. ISBN 0-7803-6375-2. S2CID 11295575.
- ^ Lloyd, S. (2002). «Computational capacity of the universe». Physical Review Letters. 88 (23): 237901–237904. arXiv:quant-ph/0110141. Bibcode:2002PhRvL..88w7901L. doi:10.1103/PhysRevLett.88.237901. PMID 12059399. S2CID 6341263.
- ^ Li, M.; Vitányi, P. (1997). An Introduction to Kolmogorov Complexity and Its Applications (2nd ed.). New York: Springer. ISBN 0-387-94868-6.
- ^ Woodward, John R. (2009). «Computable and incomputable functions and search algorithms». IEEE International Conference on Intelligent Computing and Intelligent Systems, 2009. Vol. 1. IEEE. pp. 871–875. CiteSeerX 10.1.1.158.7782.
- ^ The «only if» part was first published by Schumacher, C. W. (2000). Black Box Search : Framework and Methods (PhD dissertation). The University of Tennessee, Knoxville. ProQuest 304620040.
- ^ Rowe; Vose; Wright (2009). «Reinterpreting No Free Lunch». Evolutionary Computation. 17 (1): 117–129. doi:10.1162/evco.2009.17.1.117. PMID 19207090. S2CID 6251842.
- ^ Ho, Y. C.; Pepyne, D. L. (2002). «Simple Explanation of the No-Free-Lunch Theorem and Its Implications». Journal of Optimization Theory and Applications. 115 (3): 549–570. doi:10.1023/A:1021251113462. S2CID 123041865.
External links[edit]
- http://www.no-free-lunch.org
- Radcliffe and Surry, 1995, «Fundamental Limitations on Search Algorithms: Evolutionary Computing in Perspective» (an early published paper on NFL, appearing soon after Schaffer’s ICML paper, which in turn was based on Wolpert’s preprint; available in various formats)
- NFL publications by Thomas English
- NFL publications by Christian Igel and Marc Toussaint
- NFL and «free lunch» publications by Darrell Whitley
- Old list of publications by David Wolpert, William Macready, and Mario Koeppen on optimization and search