Argument for Consistency
The document very clearly says:
«The consistency model of a Hadoop FileSystem is one-copy-update-semantics; that of a traditional local POSIX filesystem.»
(One-copy update semantics means the file contents seen by all of the processes accessing or updating a given file would see as if only a single copy of the file existed.)
Moving forward, the document says:
- «Create. Once the close() operation on an output stream writing a newly created file has completed, in-cluster operations querying the file metadata and contents MUST immediately see the file and its data.»
- «Update. Once the close() operation on an output stream writing a newly created file has completed, in-cluster operations querying the file metadata and contents MUST immediately see the new data.
- «Delete. once a delete() operation on a path other than “/” has completed successfully, it MUST NOT be visible or accessible. Specifically, listStatus(), open() ,rename() and append() operations MUST fail.»
The above mentioned characteristics point towards the presence of «Consistency» in the HDFS.
Source: https://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/filesystem/introduction.html
Argument for Partition Tolerance
HDFS provides High Availability for both Name Nodes and Data Nodes.
Source: https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithNFS.html
Argument for Lack of Availability
It is very clearly mentioned in the documentation(under the section «Operations and failures»):
«The time to complete an operation is undefined and may depend on the implementation and on the state of the system.»
This indicates that the «Availability» in the context of CAP is missing in HDFS.
Source:
https://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/filesystem/introduction.html
Given the above mentioned arguments, I believe HDFS supports «Consistency and Partition Tolerance» and not «Availability» in the context of
CAP theorem.
In this post, we will understand about CAP theorem or Brewer’s theorem. This theorem was proposed by Eric Brewer of University of California, Berkeley.
CAP theorem, also known as Brewer’s theorem states that it is impossible for a distributed computing system to simultaneously provide all the three guarantee i.e. Consistency, Availability or Partition tolerance.
Therefore, at any point of time for any distributed system, we can choose only two of consistency, availability or partition tolerance.
Availability
Even if any of one node goes down, we can still access the data.
Consistency
You access the most recent data.
Partition Tolerance
Between the nodes, it should tolerate network outage.
The above of the three guarantees are shown in three vertices of a triangle and we are free to choose any side of the triangle.
Therefore, we can choose (Availability and Consistency) or (Availability and Partition Tolerance) or (Consistency and Partition Tolerance).
Please refer to figure below:
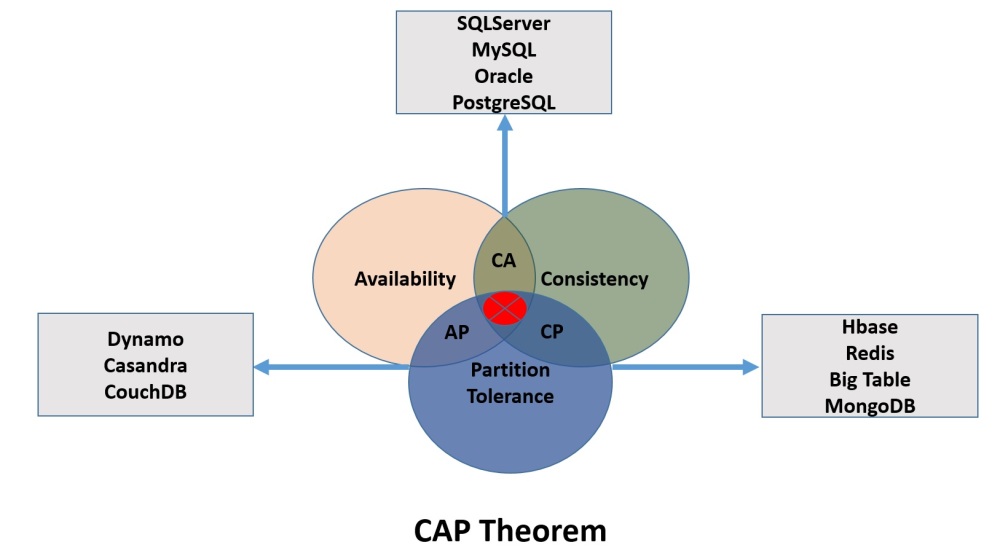
Relational Databases such as Oracle, MySQL choose Availability and Consistency while databases such as Cassandra, Couch, DynoDB choose Availability and Partition Tolerance and the databases such as HBase, MongoDB choose Consistency and Partition Tolerance.
CAP Theorem Example 1: Consistency and Partition Tolerance
Let us take an example to understand one of the use cases say (Consistency and Partition Tolerance).
These databases are usually shared or distributed data and they tend to have master or primary node through which they can handle the right request. A good example is MongoDB.
What happens when the master goes down?
In this case, usually another master will get elected and till then data can’t be read from other nodes as it is not consistent. Therefore, availability is sacrificed.
However, if the write operation went fine and there is network outage between the nodes, there is no problem because the secondary node can serve the data. Therefore, partition tolerance is achieved.
CAP Theorem Example 2: Availability and Partition Tolerance
Let us try to understand an example for Availability and Partition Tolerance.
These databases are also shared and distributed in nature and usually master-less. This means every node is equal. Cassandra is a good example of this kind of databases.
Let us consider we have an overnight batch job that writes the data from a mainframe to Cassandra database and the same database is read throughout a day. If we have to read the data as and when it is written then we might get stale data and hence the consistency is sacrificed.
Since this is the read heavy and write once use case, I don’t care about reading data immediately. I just care about once the write has happened, we can read from any of the nodes.
But Availability is one of the important parameters because if one of the nodes goes down we can be able to read the data from another backup node. The system as a whole is available.
Partition tolerance will help us in any network outage between the nodes. If any of the nodes goes down due to network issue another node can take it up.
Now a days, most of the enterprise based applications are distributed (a collection of interconnected nodes that shared data) over the internet/cloud so that increases the availability of systems. As the application grows and in terms of users and transactions counts and required persistence than big concern is database scalability.
After considering such facts In the year 2000, Eric Brewer developed one theorem that is called as CAP Theorem or Brewer’s conjecture.
CAP Theorem, states that:
“In a distribution system can only have two out of following three Consitentency, Availability, and Partition Tolerance- One of them must be a sacrifice. You can’t promise all three at a time across reading/write requests.”
- Consistency: Every read request receives the most recent write or an error.
- Availability: Every request should receive a (non-error) response, without the guarantee that it contains the most recent write.
- Partition Tolerance: The system continues to work despite an arbitrary number of messages being dropped/delayed by the network between nodes/partitions.
In the CAP theorem, consistency is quite different from the ACID database transactions. In distributed systems, partition tolerance means the system will work continue unless there is a complete network failure. If a few nodes fail then the system should keep going.
CAP Theorem Example
You can decide your system technologies based on your primary importance for Consistency, Availability and Partitioning Tolerance. Here we are just taking one example base on database selection:
CA (Consistency + Availability) Type
In this system consistency and availability is primary constraints but such type of system not provide a guarantee of one of the system is offline then the whole system is offline. Otherwise, some of the nodes will not consistent and also not have the latest information.
For Example, Oracle and MySQL are good with Consistency and Availability but not partition tolerant.
CP (Consistency + Partition Tolerant) Type
In this system, consistency and partition tolerance is primary constrains but such a system not provide a guarantee for availability and throws an error as long as the partitioned state not resolved.
For Example, Hadoop and MongoDB stored redundant data in multiple slave nodes and it tolerates an outage of a large number of nodes in the cluster.
AP (Availability + Partition Tolerant) Type
Such a system can not guarantee consistency because if updates can be made to either of a node if some nodes or network issues. This system can have different values on different nodes.
For Example, CouchDB, Dynamo DB, and Cassandra PA type database.
Note CouchDB and Dynamo DB store values in key-value pairs while Cassandra store values in the form of a column family.
See Also:
- ACID vs BASE for Database Transactions
- ACID Properties for Database Transactions
- BASE Properties for Distributed Database Transactions
References
- https://imelgrat.me/database/acid-base-databases-models/
- https://robertgreiner.com/cap-theorem-revisited/