В
языке SQL
можно использовать обычные операции
над множествами — объединение (union),
пересечение (intersection)
и разность (difference),
— позволяющие комбинировать результаты
выполнения двух и более запросов в
единую результирующую таблицу.
Все
эти операции над множествами графически
представлены на слайде.
На таблицы, которые могут комбинироваться
с помощью операций над множествами,
накладываются определенные ограничения.
Самое важное из них состоит в том, что
таблицы должны быть совместимы
по операции —
т.е. они должны иметь одну и ту же
структуру. Это означает, что таблицы
должны иметь одинаковое количество
столбцов, причем в соответствующих
столбцах должны размещаться данные
одного и того же типа и длины. Обязанность
убедиться в том, что значения данных
соответствующих столбцов принадлежат
одному и тому же домену, возлагается на
пользователя. Например, мало смысла в
том, чтобы объединять столбец с данными
о возрасте работников с информацией о
количестве комнат в сдаваемых в аренду
объектах, хотя оба столбца будут иметь
один и тот же тип данных — SMALLINT
Три
операции над множествами, предусмотренные
стандартом ISO,
носят название
UNION,
INTERSECT
и EXCEPT.
При
указании в формате конструкции ключевого
слова CORRESPONDING
BY
операция над множествами выполняется
для указанных столбцов. Если задано
только ключевое слово CORRESPONDING,
а конструкция BY
отсутствует, операция над множествами
выполняется
для столбцов, которые являются общими
для обеих таблиц. Если указано
ключевое слово ALL,
результирующая таблица может содержать
повторяющиеся
строки.
Одни
диалекты языка SQL
не поддерживают операций INTERSECT
и EXCEPT,
a
в других вместо ключевого слова EXCEPT
используется ключевое слово MINUS.
Остальные
операции реляционной алгебры реализуются
в представленных ниже языковых
конструкциях.
Операция
декартового произведения отношений
реализуется в предложении FROM
команды SELECT.
Перечисление в предложении FROM
нескольких реляционных таблиц через
запятую приведет к их перемножению.
Операция
естественного соединения реализуется
в предложении FROM
команды SELECT
путем соединения таблиц с помощью
ключевых слов INNER
JOIN,
LEFT
JOIN,
RIGHT
JOIN,
OUTER
JOIN
с указанием столбцов связи.
Операция
проекции задается перечислением столбцов
таблицы предложения FROM.
Для того, чтобы обеспечить уникальность
каждой строки результата, используется
ключевое слово DISTINCT.
Операция
выборки определяется предложением
WHERE
команды SELECT.
Предикат выборки задается в форме
логического выражения.
Лекция 17 (db_l17.Ppt). Построение баз данных с помощью sql. Манипулирование данными в sql
В
состав языка SQL
входят язык описания данных, позволяющий
управлять таблицами, и язык манипулирования
данными, служащий для управления данными
(слайд
2).
17.1. Построение баз данных с помощью sql
17.1.1. Команда создания таблицы – create table
Создание
таблицы выполняется при помощи команды
CREATE TABLE. Обобщенный синтаксис команды
следующий (слайд
3).
Т.е.
после задания имени таблицы через
запятую в круглых скобках должны быть
перечислены все предложения, определяющие
отдельные элементы таблицы – столбцы
или ограничения целостности:
имя_таблицы
— идентификатор создаваемой таблицы,
который в общем случае строится из имени
базы данных, имени владельца таблицы и
имени самой таблицы. При этом комбинация
имени таблицы и ее владельца должна
быть уникальной в пределах базы данных.
Если таблица создается не в текущей
базе данных, в ее идентификатор необходимо
включить имя базы данных.
определение_столбца
— задание имени, типа данных и параметров
отдельного столбца таблицы. Названия
столбцов должны соответствовать правилам
для идентификаторов и быть уникальными
в пределах таблицы.
определение_ограничения_таблицы
– задание некоторого ограничения
целостности на уровне таблицы.
Описание
столбцов
Как
видно из синтаксиса команды CREATE TABLE, для
каждого столбца указывается предложение
<определение_столбца>, с помощью
которого и задаются свойства столбца.
Предложение имеет следующий синтаксис
(слайд
3):
Рассмотрим
назначение и использование параметров.
Имя_столбца
— идентификатор, задающий имя столбца
таблицы.
тип_данных
— задает тип данных столбца. Если при
определении столбца явно не указано
ограничение на хранения значений NULL,
то будут использованы свойства типа
данных, т.е. если выбранный тип данных
позволяет хранить значения NULL, то и в
столбце можно будет хранить значения
NULL. Если же при определении столбца в
команде CREATE ТАBLE явно будет разрешено
или запрещено хранение значений NULL, то
свойства типа данных будут перекрыты
установленным на уровне столбца
ограничением. Например, если тип данных
позволяет хранить значения NULL, а на
уровне столбца будет установлен запрет,
то попытка вставки значения NULL в столбец
закончится ошибкой.
ограничение_столбца
— с помощью этого предложения указываются
ограничения, которые будут определены
для столбца. Синтаксис предложения
следующий (слайд
4):
Рассмотрим
назначение параметров.
CONSTRAINT
— необязательное ключевое слово, после
которого указывается название ограничения
на значения столбца (имя_ограничения).
Имена ограничений должны быть уникальны
в пределах базы данных.
DEFAULT
— задает значение по умолчанию для
столбца. Это значение будет использовано
при вставке строки, если для столбца
явно не указано никакое значение.
NULL|NOT
NULL — ключевые слова, разрешающие (NULL)
или запрещающие (NOT NULL) хранение в столбце
значений NULL. Если для столбца не задано
значение по умолчанию, то при вставке
строки с неизвестным значением для
столбца будет предприниматься попытка
вставки в столбец значения NULL. Если при
этом для столбца указано ограничение
NOT NULL, то попытка вставки строки будет
отклонена, и пользователь получит
соответствующее сообщение об ошибке.
PRIMARY
KEY — определение первичного ключа на
уровне одного столбца (т.е. первичный
ключ будет состоять только из значений
одного столбца). Если необходимо
сформировать первичный ключ на базе
двух и более столбцов, то такое ограничение
целостности должно быть задано на уровне
таблицы. При этом следует помнить, что
для каждой таблицы может быть создан
только один первичный ключ.
UNIQUE
— указание на создание для столбца
ограничения целостности UNIQUE, что позволит
гарантировать уникальность каждого
отдельного значения в столбце в пределах
этого столбца. В таблице может быть
создано несколько ограничений целостности
UNIQUE.
FOREIGN
KEY … REFERENCES — указание на то, что столбец
будет служить внешним ключом для таблицы,
имя которой задается с помощью параметра
<имя_главной_таблицы>.
(имя_столбца
[,…,n]) — столбец или список перечисленных
через запятую столбцов главной таблицы,
входящих в ограничение FOREIGN KEY. При этом
столбцы, входящие во внешний ключ, могут
ссылаться только на столбцы первичного
ключа или столбцы с ограничением UNIQUE
таблицы.
ON
DELETE {CASCADE | NO ACTION} — эти ключевые слова
определяют действия, предпринимаемые
при удалении строки из главной таблицы.
Если указано ключевое слово CASCADE, то при
удалении строки из главной (родительской)
таблицы строка в зависимой таблице
также будет удалена. При указании
ключевого слова NO ACTION в подобном случае
будет выдана ошибка. Значением по
умолчанию является вариант NO ACTION.
ON
UPDATE {CASCADE | NO ACTION} — эти ключевые слова
определяют действия, предпринимаемые
при модификации строки главной таблицы.
Если указано ключевое слово CASCADE, то при
модификации строки из главной
(родительской) таблицы строка в зависимой
таблице также будет модифицирована.
При использовании ключевого слова NO
ACTION в подобном случае будет выдана
ошибка. Значением по умолчанию является
вариант NO ACTION.
CHECK
— ограничение целостности, инициирующее
контроль вводимых в столбец (или столбцы)
значений.
логическое_выражение
— логическое выражение, используемое
для ограничения CHECK.
Ограничения
на уровне таблицы
Синтаксис
команды CREATE TABLE предусматривает
использование предложения
<ограничение_таблицы>, с помощью
которого определяются ограничения
целостности на уровне таблицы. Синтаксис
предложения следующий (слайд
5).
Назначение
параметров совпадает с назначением
аналогичных параметров предложения
<ограничение_столбца. Тем не менее,
в предложении <ограничение_таблицы>
имеются некоторые новые параметры:
имя_колонки
— столбец (или список столбцов), на
которые необходимо наложить какие-либо
ограничения целостности.
[ASC
| DESC] — метод упорядочивания данных в
индексе. Индекс создается при указании
ключевых слов PRIMARY KEY, UNIQUE. При указании
значения ASC данные в индексе будут
упорядочены по возрастанию, при указании
значения DESC — по убыванию. По умолчанию
используется значение ASC.
Примеры
создания таблиц
В
качестве примера рассмотрим инструкции
создания таблиц базы данных «Сессия»:
Таблица
«Студенты» состоит из следующих столбцов:
ID_Студент
– тип данных INTEGER, уникальный ключ;
Фамилия
– тип данных CHAR, длина 30;
Имя
— тип данных CHAR, длина 15;
Отчество
— тип данных CHAR, длина 20;
Номер_группы
— тип данных CHAR, длина 6;
Адрес
— тип данных CHAR, длина 30;
Телефон
— тип данных CHAR, длина 8.
Создание
таблицы выполнялось с помощью следующей
команды (слайд
6).
На
все столбцы таблицы, кроме столбцов
Адрес
и Телефон,
наложены ограничения NOT
NULL,
запрещающие ввод строки при неопределенном
значении столбца.
Для
создания таблицы «Дисциплины» была
использована команда (слайд
7).
Таблица
содержит 2 столбца (ID_Дисциплина,
Наименование).
На
столбцы ID_Дисциплина,
Наименование
наложены ограничения NOT
NULL,
запрещающие ввод строки при неопределенном
значении столбца.
Столбец
ID_Дисциплина
объявлен первичным ключом, а на значения,
вводимые в столбец Наименование,
наложено условие уникальности.
Таблица
«Учебный_план» включает в себя следующие
столбцы:
ID_План
– тип данных INTEGER, столбец уникального
ключа;
ID_Дисциплина
– тип данных INTEGER;
Семестр
— тип данных INTEGER;
Количество_часов
— тип данных INTEGER;
ID_Преподаватель
— тип данных INTEGER.
Создание
таблицы выполнялось с помощью следующей
команды (слайд
8).
Для
значений столбца Семестр
сформулировано логическое выражение,
разрешающее вводить только значения
от 1 до 10.
Таблица
«Сводная_ведомость» состоит из следующих
столбцов:
ID_Студент
– тип данных INTEGER, столбец уникального
ключа;
ID_План
– тип данных INTEGER, столбец уникального
ключа;
Оценка
— тип данных INTEGER;
Дата_сдачи
— тип данных DATETIME;
ID_Преподаватель
— тип данных INTEGER.
Создание
таблицы выполнялось с помощью следующей
команды (слайд
9).
На
все столбцы таблицы наложены ограничения
NOT
NULL,
запрещающие ввод строки при неопределенном
значении столбца.
Для
значений столбца Оценка
сформулировано логическое выражение,
разрешающее вводить только значения
от 0 до 5: 0 – незачет, 1 – зачет, 2 –
неудовлетворительно, 3 – удовлетворительно,
4 – хорошо, 5 – отлично.
И,
наконец, перечислим столбцы
«Кадровый_состав»:
ID_Преподаватель
– тип данных INTEGER, уникальный ключ;
Фамилия
– тип данных CHAR, длина 30;
Имя
— тип данных CHAR, длина 15;
Отчество
— тип данных CHAR, длина 20;
Должность
— тип данных CHAR, длина 20;
Кафедра
— тип данных CHAR, длина 3;
Адрес
— тип данных CHAR, длина 30;
Телефон
— тип данных CHAR, длина 8.
Создание
таблицы выполнялось с помощью следующей
команды (слайд
10).
На
все столбцы таблицы, кроме столбцов
Адрес
и Телефон,
наложены ограничения NOT
NULL,
запрещающие ввод строки при неопределенном
значении столбца.
Для
таблиц «Учебный_план» и «Сводная_ведомость»
должны быть построены внешние ключи,
связывающие таблицы базы данных «Сессия»:
FK_Дисциплина
– внешний ключ, связывающий таблицы
«Учебный_план» и «Дисциплины» по столбцу
ID_Дисциплина;
FK_Кадровый_состав
– внешний ключ, связывающий таблицы
«Учебный_план» и «Кадровый_состав» по
столбцу ID_Преподаватель;
FK_Студент
– внешний ключ, связывающий таблицы
«Сводная_ведомость» и «Студенты» по
столбцу ID_Студент;
FK_План
– внешний ключ, связывающий таблицы
«Сводная_ведомость» и «Учебный_план»
по столбцу ID_План.
Добавление
внешних ключей в таблицы рассмотрим
далее при обсуждении возможностей
команды ALTER
TABLE.
Соседние файлы в предмете Базы данных
- #
- #
- #
- #
- #
- #
- #
3.5. ���������� �������� ����������� ������� ������������ SELECT
� ������� ����������� SELECT ����� ����������� ����� �������� ����������� ������� [2].
�������� (�������������� ������������) ������� ��������� �� ��� �� �����, ������� ������������� �������� ��������. ������:
SELECT * FROM ����� WHER ������ = '������' AND ����� > 200;
�������� (������������ ������������) ������� ��������� �� ��������� �� �������� (� �������� �������) � ����������� ����������� ���������� ���������� �����. ������:
SELECT DISTINCT �����, �����, ������ FROM �����;
����������� ���� ������ �������� �� ������, ������� ���� ���� � ������, ���� �� ������, ���� � ����� ��������. ������:
SELECT �����, ������, ����� FROM ����� WHER ������ = '�����' UNION SELECT �����, ������, ����� FROM ����� WHER � = '�';
����������� ���� ������ �������� ������ �� ������, ������� ���� � � ������, � �� ������. ������:
SELECT �� FROM ������ WHERE �� IN ( SELECT �� FROM ����);
�������� ���� ������ �������� ������ �� ������, ������� ���� � ������, �� ����������� �� ������. ������:
SELECT �� FROM ������ WHERE �� NOT IN ( SELECT �� FROM ����);
��������� ������������ ������ � ��������� ���� ���������� ���� �������� ����������� � �. 3.2.1-3.2.6.
����� ������� ���� ���������� ������ �������� ����� ����������� �������� �������, ������� ����� ����� ���� ����������� ������������ SELECT � ���������������� ���������� ������������.
3.4 | ���������� | 3.6
Основы реляционной алгебры
Реляционная алгебра базируется на теории множеств и является основой логики работы баз данных.
Основы теории реляционных баз данных, равно как и операции реляционной алгебры, были предложены Эдгаром Коддом во время работы в компании IBM

Операции реляционной алгебры
Основные восемь операций реляционной алгебры:
Традиционные операции над множествами:
- Объединение
- Пересечение
- Вычитание
- Декартово произведение
Специальные реляционные операции:
- Выборка
- Проекция
- Соединение
- Деление
Результатом любой операции алгебры над отношениями является еще одно отношение, которое можно потом так же использовать в других операциях.
Проекция
Проекция является операцией, при которой из отношения выделяются атрибуты только из указанных доменов, то есть из таблицы выбираются только нужные столбцы, при этом, если получится несколько одинаковых кортежей, то в результирующем отношении остается только по одному экземпляру подобного кортежа.
Таблица People
| Name | Age | Weight |
|---|---|---|
| Harry | 34 | 80 |
| Sally | 28 | 64 |
| George | 29 | 70 |
| Peter | 34 | 80 |
Результат проекции: π(Age, Weight)People
| Age | Weight |
|---|---|
| 28 | 64 |
| 29 | 70 |
| 34 | 80 |
Эквивалентный SQL-запрос:
SELECT DISTINCT Age, Weight FROM People;
Примечательно, что в SQL для полного соответствия операции проекции необходимо указывать ключевое слово DISTINCT, поскольку без него строка с возрастом 34 и весом 80 отобразится дважды, что отличается от результата реляционной операции проекции1.
Выборка
Выборка — это операция, которая выделяет множество строк в таблице, удовлетворяющих заданным условиям.
Условием может быть любое логическое выражение.
Пример
Таблица People
| Name | Age | Weight |
|---|---|---|
| Harry | 34 | 80 |
| Sally | 28 | 64 |
| George | 29 | 70 |
| Helena | 54 | 54 |
| Peter | 34 | 80 |
Результаты выборки: σ(Age≥34)People
| Name | Age | Weight |
|---|---|---|
| Harry | 34 | 80 |
| Helena | 54 | 54 |
| Peter | 34 | 80 |
Эквивалентный SQL-запрос:
SELECT * FROM People WHERE Age >= 34;
Выборка и проекция
Совместим операторы проекции и выборки. Мы можем это сделать, потому что любой из операторов в результате возвращает отношение и в качестве аргументов использует также отношение.
Исходная таблица People
| id | name | age | weight |
|---|---|---|---|
| 1 | Harry | 34 | 80 |
| 2 | Sally | 28 | 64 |
| 3 | George | 29 | 70 |
| 4 | Helena | 54 | 54 |
| 5 | Peter | 34 | 80 |
Результаты выборки: π(name, age)σ(age>50)People
| name | age |
|---|---|
| Helena | 54 |
Эквивалентный SQL-запрос:
SELECT name, age FROM People WHERE age > 50;
или
SELECT name, age FROM (SELECT * FROM People WHERE age > 50) AS t;
Объединение
Результатом объединения отношений A и B будет отношение с тем же заголовком, что и у совместимых по типу отношений A и B, и телом, состоящим из кортежей, принадлежащих или A, или B, или обоим отношениям.

Таблица People
| id | name | age | weight |
|---|---|---|---|
| 1 | Harry | 34 | 80 |
| 2 | Sally | 28 | 64 |
| 3 | George | 29 | 70 |
| 4 | Helena | 54 | 54 |
| 5 | Peter | 34 | 80 |
Таблица Characters
| id | name | age | weight |
|---|---|---|---|
| 1 | Daffy | 24 | 19 |
| 2 | Donald | 25 | 23 |
| 3 | Scrooge | 81 | 27 |
Результат объединения таблиц
Объединенная таблица
| id | name | age | weight |
|---|---|---|---|
| 1 | Harry | 34 | 80 |
| 2 | Sally | 28 | 64 |
| 3 | George | 29 | 70 |
| 4 | Helena | 54 | 54 |
| 5 | Peter | 34 | 80 |
| 1 | Daffy | 24 | 19 |
| 2 | Donald | 25 | 23 |
| 3 | Scrooge | 81 | 27 |
Эквивалентный SQL запрос:
SELECT * FROM People UNION SELECT * FROM Characters;
Вопрос: как отсортировать результат объединения двух таблиц по возрасту?
.notes: SELECT * FROM People UNION SELECT * FROM Characters ORDER BY age;
Пересечение
Результатом пересечения отношений A и B будет отношение с тем же заголовком, что и у отношений A и B, и телом, состоящим из кортежей, принадлежащих одновременно обоим отношениям A и B.

Таблица People
| id | name | age | weight |
|---|---|---|---|
| 1 | Harry | 34 | 80 |
| 2 | Sally | 28 | 64 |
| 3 | George | 29 | 70 |
| 4 | Helena | 54 | 54 |
| 5 | Peter | 34 | 80 |
Таблица Characters
| id | name | age | weight |
|---|---|---|---|
| 1 | Daffy | 24 | 19 |
| 2 | Donald | 25 | 23 |
| 3 | Scrooge | 81 | 27 |
| 4 | George | 29 | 70 |
| 5 | Sally | 28 | 64 |
Результат пересечения таблиц
Пересечение таблиц
| name | age | weight |
|---|---|---|
| Sally | 28 | 64 |
| George | 29 | 70 |
Эквивалентный SQL запрос MSSQL и Access:
TSQL> SELECT name, age, weight FROM People INTERSECT SELECT name, age, weight FROM Characters;
Эквивалентный запрос в MySql:
-- mysql не поддерживает операцию INTERSECT mysql> SELECT DISTINCT People.name AS name, People.age AS age, People.weight AS weight FROM People INNER JOIN Characters USING(name, age, weight);
Вычитание
Результатом разности отношений A и B будет отношение с тем же заголовком, что и у совместимых по типу отношений A и B, и телом, состоящим из кортежей, принадлежащих отношению A и не принадлежащих отношению B.

Результат разности
| name | age | weight |
|---|---|---|
| Harry | 34 | 80 |
| Helena | 54 | 54 |
| Peter | 34 | 80 |
Эквивалентный SQL запрос MSSQL и Access:
TSQL> SELECT name, age, weight FROM People EXCEPT SELECT name, age, weight FROM Characters;
Эквивалентный запрос в MySql:
-- mysql не поддерживает операцию EXCEPT mysql> SELECT DISTINCT People.name AS name, People.age AS age, People.weight AS weight FROM People LEFT OUTER JOIN Characters USING (name, age, weight) WHERE Characters.name IS NULL;
Декартово произведение
При выполнении прямого произведения двух отношений производится отношение, кортежи которого являются конкатенацией (сцеплением) кортежей первого и второго операндов.
Пусть даны соотношения (таблицы):
Таблица Cartoons
| id_cartoon | name_cartoon |
|---|---|
| 1 | The Simpsons |
| 2 | Family Guy |
Таблица Channels
| id_channel | name_channel |
|---|---|
| 1 | 1+1 |
| 2 | СТБ |
Результат произведения Cartoons × Channels
| id_cartoon | name_cartoon | id_channel | name_channel |
|---|---|---|---|
| 1 | The Simpsons | 1 | 1+1 |
| 2 | Family Guy | 1 | 1+1 |
| 1 | The Simpsons | 2 | СТБ |
| 2 | Family Guy | 2 | СТБ |
Декартово произведение
Эквивалентный SQL запрос:
SELECT * FROM Cartoons, Channels;
Альтернативный запрос:
SELECT * FROM Cartoons CROSS JOIN Channels;
Деление
Деление отношений — создает новое отношение, содержащее атрибуты первого
отношения, отсутствующие во втором отношении и кортежи первого отношения,
которые совпали кортежами второго.
Для выполнения этой операции второе отношения должно содержать лишь атрибуты,
совпадающие с атрибутами первого.
Операция деления полезна тогда, когда запрос содержит слово «все».
Даны следующие соотношения:
Таблица CartoonsChannels
| id_cartoon | name_cartoon | name_channel |
|---|---|---|
| 0 | The Simpsons | Inter |
| 0 | The Simpsons | 1+1 |
| 0 | The Simpsons | СТБ |
| 1 | Family Guy | Inter |
| 1 | Family Guy | 1+1 |
| 2 | Duck Tales | СТБ |
| 2 | Duck Tales | 1+1 |
Таблица Channels
| name_channel |
|---|
| Inter |
| 1+1 |
Результат деления
| id | name_cartoon |
|---|---|
| 0 | The Simpsons |
| 1 | Family Guy |
Пояснение
Family Guy и The Simpsons — мультфильмы, которые показывались и на Inter и на 1+1 (условие во второй таблице).
При этом Duck Tales не показывалось по Inter, потому был исключён из результирующей таблицы.
Эквивалентный SQL-запрос:
-- mysql не поддерживает операцию DIVIDE mysql>SELECT DISTINCT c1.id_cartoon AS id, c1.name_cartoon AS name_cartoon FROM CartoonsChanels AS c1 WHERE NOT EXISTS ( SELECT Chanels.name_channel FROM Chanels WHERE Chanels.name_channel NOT IN ( SELECT c2.name_channel FROM CartoonsChanels AS c2 WHERE c2.name_cartoon=c1.name_cartoon ) );
Соединение
Операция соединения есть результат последовательного применения операций декартового произведения и выборки.
Если в отношениях и имеются атрибуты с одинаковыми наименованиями, то перед выполнением соединения
такие атрибуты необходимо переименовать.
Пример
Есть таблица Cartoons:
| id_catroon | name_cartoon | channel_id |
|---|---|---|
| 1 | The Simpsons | 1 |
| 2 | Family Guy | 1 |
| 3 | Duck Tales | 2 |
и таблица Channels:
| id_channel | name_channel |
|---|---|
| 1 | Inter |
| 2 | ICTV |
Соединим их с выборкой σ(id_channel=channel_id)(Произведение)
Результат соединения
Первый этап, декартовое произведение:
SELECT * FROM Cartoons, Channels;
| id_catroons | name_cartoon | channel_id | id_channel | name_channel |
|---|---|---|---|---|
| 1 | The Simpsons | 1 | 1 | Inter |
| 1 | The Simpsons | 1 | 2 | ICTV |
| 2 | Family Guy | 1 | 1 | Inter |
| 2 | Family Guy | 1 | 2 | ICTV |
| 3 | Duck Tales | 2 | 1 | Inter |
| 3 | Duck Tales | 2 | 2 | ICTV |
Второй этап, выборка:
SELECT * FROM Cartoons, Channels WHERE Cartoons.channel_id=Channels.id_channel;
| id_catroons | name_cartoon | channel_id | id_channel | name_channel |
|---|---|---|---|---|
| 1 | The Simpsons | 1 | 1 | Inter |
| 2 | Family Guy | 1 | 1 | Inter |
| 3 | Duck Tales | 2 | 2 | ICTV |
Вопрос: как получить только столбцы name_cartoon и name_channel?
.notes: SELECT Cartoons.name_cartoon, Channels.name_channel FROM Cartoons, Channels WHERE Cartoons.channel_id=Channels.id_channel;
Inner Join
Выбираются только совпадающие данные из объединяемых таблиц.
SELECT * FROM Cartoons INNER JOIN Channels ON Cartoons.channel_id = Channels.id_channel;
| id_catroons | name_cartoon | channel_id | id_channel | name_channel |
|---|---|---|---|---|
| 1 | The Simpsons | 1 | 1 | Inter |
| 2 | Family Guy | 1 | 1 | Inter |
| 3 | Duck Tales | 2 | 2 | ICTV |
Внутреннее объединение INNER JOIN (синоним JOIN, ключевое слово INNER можно опустить).
Outer Join
Чтобы получить данные, которые подходят по условию частично, необходимо использовать
внешнее объединение — OUTER JOIN.
Такое объединение вернет данные из обеих таблиц (совпадающие по условию объединения) ПЛЮС
дополнит выборку оставшимися данными из внешней таблицы, которые по условию не подходят,
заполнив недостающие данные значением NULL.
Существует два типа внешнего объединения OUTER JOIN — LEFT OUTER JOIN и RIGHT OUTER JOIN.
Работают они одинаково, разница заключается в том что LEFT — указывает что «внешней» таблицей
будет находящаяся слева (в нашем примере это таблица Cartoons), а RIGHT — что «внешней»
таблица будет таблица справа (в нашем примере это таблица Channels).
Left Outer Join
В случае с left join из главной таблицы будут выбраны все записи, даже если в присоединяемой
таблице нет совпадений, то есть условие не учитывает присоединяемую (правую) таблицу.
Пример:
SELECT * FROM Cartoons OUTER LEFT JOIN Channels ON Cartoons.channel_id = Channels.id_channel;
| id_catroons | name_cartoon | channel_id | id_channel | name_channel |
| 1 | The Simpsons | 1 | 1 | Inter |
| 2 | Family Guy | 1 | 1 | Inter |
| 3 | Duck Tales | 2 | 2 | ICTV |
| 4 | Futurama | 10 | NULL | NULL |
| 5 | Spanch Bob | 15 | NULL | NULL |
Right Outer Join
Right join отображает все строки удовлетворяющие правой части условия condition,
даже если они не имеют соответствия в главной (левой) таблице:
Пример:
SELECT * FROM Cartoons OUTER RIGHT JOIN Channels ON Cartoons.channel_id = Channels.id_channel;
| id_catroons | name_cartoon | channel_id | id_channel | name_channel |
| 1 | The Simpsons | 1 | 1 | Inter |
| 2 | Family Guy | 1 | 1 | Inter |
| 3 | Duck Tales | 2 | 2 | ICTV |
| NULL | NULL | NULL | 3 | 1+1 |
| NULL | NULL | NULL | 4 | СТБ |
| NULL | NULL | NULL | 5 | 2+2 |
Full Join
Full outer join (ключевое слово outer можно опустить) необходим для отображения всех возможных
комбинаций строк из нескольких таблиц. Иными словами, это объединение результатов left и right join.
SELECT column_name(s) FROM table1 FULL OUTER JOIN table2 ON table1.column_name=table2.column_name;
Некоторые СУБД не поддерживают такую функциональность (например, MySQL), в таких случаях обычно
используют объединение двух запросов:
SELECT * FROM Cartoons LEFT JOIN Channels ON Cartoons.channel_id = Channels.id_channel UNION SELECT * FROM Cartoons OUTER RIGHT JOIN Channels ON Cartoons.channel_id = Channels.id_channel;
Результат Full Join
| id_catroons | name_cartoon | channel_id | id_channel | name_channel |
| 1 | The Simpsons | 1 | 1 | Inter |
| 2 | Family Guy | 1 | 1 | Inter |
| 3 | Duck Tales | 2 | 2 | ICTV |
| 4 | Futurama | 10 | NULL | NULL |
| 5 | Spanch Bob | 15 | NULL | NULL |
| NULL | NULL | NULL | 3 | 1+1 |
| NULL | NULL | NULL | 4 | СТБ |
| NULL | NULL | NULL | 5 | 2+2 |
Ссылки
- Основы реляционной алгебры
- Реляционная алгебра. Операции реляционной алгебры
- Язык SQL и реляционная алгебра
- Union, Difference, Intersection, and Division in MySQL
12.4. Использование SQL для выбора информации из нескольких таблиц
До сих пор мы рассматривали выбор информации из единственной таблицы. Можно запрашивать информацию из нескольких таблиц, реализуя описанные в соответствующем разделе учебника реляционные операции. Стоит упомянуть, что полное рассмотрение темы выходит за рамки данного учебника. Подробно этот вопрос можно изучить при помощи, например, [
[
3.1
]
,
[
11.2
]
]. Рассмотрим некоторые примеры того, как это делается.
Как правило, в тех случаях когда возникает необходимость выбирать информацию из разных таблиц, они тем или иным образом связаны друг с другом, например отношениями один к многим или один к одному по некоторому полю.
Еще раз вернемся к примеру из
«Физические модели данных (внутренний уровень)»
. Рассмотрим соответствующую ER-диаграмму (
рис.
12.2.).
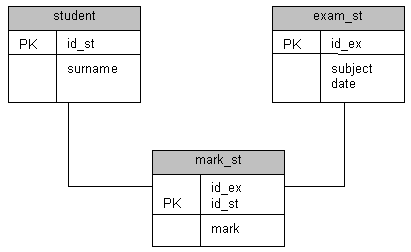
Рис.
12.2.
Пример связанных таблиц
В этом примере тоже присутствуют связанные таблицы. Рассмотрим таблицы student, mark_st и exam_st.
Таблица mark_st связана с таблицей exam_st по полю id_ex.
Таблица mark_st связана с таблицей student по полю id_st.
Допустим, требуется распечатать список студентов с оценками, которые они получили на экзаменах. Для этого необходимо выполнить следующий запрос:
SELECT student.surname, mark_st.id_ex, mark_st.mark FROM student, mark_st WHERE student.id_st = mark_st.id_st
Отметим следующие изменения по сравнению с запросами к одной таблице.
- В секции FROM указаны две таблицы.
- Так как таблиц стало больше одной, появилась некоторая неоднозначность при упоминании полей. Так, во многих случаях неизвестно, из какой таблицы из списка FROM брать поле. Для устранения неоднозначности имена полей указываются с префиксом – именем таблицы. Имя таблицы от имени поля отделяется точкой.
- В предложении WHERE указано условие соединения таблиц.
Нетрудно заметить, что использование префиксов-имен таблиц сильно загромождает запрос. Для того чтобы избежать подобного загромождения, используются псевдонимы. Так, можно переписать предыдущий запрос следующим образом:
SELECT E.surname, M.id_ex, M.mark FROM student E, mark_st M WHERE E.id_st = M. id_st
12.5. Использование SQL для вставки, редактирования и удаления данных в таблицах
Для добавления данных в таблицу в стандарте SQL предусмотрена команда INSERT. Рассмотрим ряд примеров запросов.
INSERT INTO mark_st VALUES (1, 2, 5)
Данный запрос вставляет в таблицу mark_st строку, содержащую значения, перечисленные в списке VALUES. Если не нужно указывать значение какого-то поля, можно присвоить ему NULL:
INSERT INTO mark VALUES (1, 2, NULL)
В случае если необходимо использование для некоторых полей значений по умолчанию, SQL позволяет явно указать, какие поля необходимо заполнить конкретными данными, а какие – значениями по умолчанию:
INSERT INTO mark_st (id_st, id_ex) VALUES (1, 2)
Для удаления данных из таблицы существует команда DELETE:
Этот запрос удаляет все данные из таблицы student.
Можно ограничить диапазон удаляемой информации следующим образом:
DELETE FROM student WHERE surname > 'И'
Для обновления данных используется команда UPDATE.
UPDATE mark_st SET mark = '5' WHERE id_st = 100 AND id_ex = 10
При помощи этого запроса изменится на «5» оценка у студента с кодом 100 по экзамену с кодом 10.
12.5. Язык SQL и операции реляционной алгебры
Язык SQL является средством выражения мощного математического аппарата теории множеств и реляционной алгебры. В данном разделе рассматривается связь операторов языка SQL с операциями реляционной алгебры и теории множеств.
Операция объединения
Средствами языка SQL операция объединения представляется следующим образом:
SELECT * FROM A UNION SELECT * FROM B
Операция разности
Средствами языка SQL операция разности представляется следующим образом:
SELECT * FROM A EXCEPT SELECT * FROM B
Операция проекции
SELECT Fieldi1, ..., Fieldin FROM A
Операция выборки (селекции)
SELECT * FROM A WHERE (<condition>)
Операция пересечения
SELECT * FROM A INTERSECT SELECT * FROM B
Операция соединения, эквисоединения

Если  – операция «=», то это эквисоединение.
– операция «=», то это эквисоединение.
Операция естественного соединения
Пусть есть отношения A(X1, …, Xn, A1, …, Am) и B(X1, …, Xn, B1, …, Br).
SELECT A.X1, ..., A.Xn, A.A1, ..., A.Am, B.B1, ..., B.Br FROM A, B WHERE (A.X1 = B.X1) AND ... AND (A.Xn = B.Xn)
Краткие итоги: В лекции дается общая характеристика операторов языка SQL, используемых, в частности, для работы с базой данных в интерактивном режиме (создание таблиц, выбор информации из таблиц, добавление, удаление и модификация элементов). Дается понятие интерактивного режима работы с SQL. Рассматриваются основные операторы SQL, используемые для манипулирования данными (выбор информации из таблиц, добавление, удаление и модификация элементов). Приводятся примеры записи запросов к базе данных на языке SQL с использованием операторов select, insert, update, delete. Рассматривается связь между операциями реляционной алгебры и операторами языка SQL.
Более подробно материалы лекции рассматриваются в [
[
3.1
]
—
[
5.4
]
].
Содержание
- 1 Операции над данными
- 1.1 Расширение
- 1.2 Агрегирование
- 2 Свойства реляционной алгебры
- 2.1 Свойства операций
- 2.2 Базис операций
- 2.3 Ограничения реляционной алгебры
- 2.4 Применимость
- 3 Реляционная алгебра и SQL
- 3.1 Унарные операции
- 3.1.1 Проекция [math]pi_{A_1,A_2,A_3,dotsc,A_N}(R)[/math]
- 3.1.2 Фильтрация [math]sigma_{Condition}(R)[/math]
- 3.1.3 Переименование [math]rho_{a=b}(R)[/math]
- 3.2 Операции над множествами
- 3.2.1 Объединение [math]R1 cup R2[/math]
- 3.2.2 Пересечение [math]R1 cap R2[/math]=
- 3.2.3 Разность [math]R1 — R2[/math]
- 3.3 Операции над данными
- 3.3.1 Расширение [math]sigma_{A=expr}(R)[/math]
- 3.3.2 Агрегирование [math]Function_{Q, A}(R) [/math]
- 3.4 Соединения
- 3.4.1 Полное [math]R_1 times R_2 [/math]
- 3.4.2 Естественное [math]R_1 bowtie R_2[/math]
- 3.4.3 Внешние [math]R_1 times R_2[/math]
- 3.4.4 Полусоединений нет
- 3.5 Структура SQL-запроса
- 3.6 Примеры
- 3.1 Унарные операции
- 4 Литература
Операции над данными
Расширение
| Определение: |
| Операция расширения позволяет добавить вычисляемый атрибут. Она принимает отношение и возвращает другое, идентичное заданному, добавляя к нему дополнительный атрибут, полученный в результате вычисления произвольных скалярных функций от значений атрибутов. |
Пример: отношение R со значением веса в фунтах
| Id | Weight |
|---|---|
| 1 | 12.0 |
| 2 | 17.0 |
Примером будет — мы добавим значение веса в граммах:
| Id | Weight | GMWT |
|---|---|---|
| 1 | 12.0 | 5448.0 |
| 2 | 17.0 | 7718.0 |
Агрегирование
| Определение: |
| Агрегирование позволяет выполнить функцию на нескольних кортежах сразу, с указанием сохраняемых и агрегируемого атрибутов. При этом кортежи группируются по значениям сохраняемых атрибутов, затем над каждой группой применяется функция агрегации. |
К типичным разновидностям относятся `SUM`, `COUNT`, `AVG`, `MAX`, `MIN`, `ALL`, `ANY`.
Пример операции `SUM` над отношением
| Supplier | Price | Items |
|---|---|---|
| 1 | 1 | 4 |
| 1 | 2 | 5 |
| 2 | 3 | 6 |
Посчитаем , получаем:
| Supplier | Total |
|---|---|
| 1 | 14 |
| 2 | 18 |
Ещё один хороший пример — сумма по пустому множеству аттрибутов. Посчитаем от того же отношения и получим
| Total |
|---|
| 32 |
Свойства реляционной алгебры
Свойства операций
| Определение: |
| Идемпотентность — свойство при повторном применении операции давать тот же результат. Примеры: унарные (вторая проекция на одно и то же множество атрибутов не влияет на результат) и (две фильтрации не влияют на результат), бинарные (естественное соединение идемпотентно и слева, и справа), , (аналогично и объединение, и пересечение идемпотентно и слева, и справа), (внешние соединения тоже идемпотентны и слева, и справа), (только справа), (только слева), (только справа). |
| Определение: |
| Коммутативность — возможность перестановки двух аргументов (). Пример: (ествественное соединение коммутативно), , (из теории множеств коммутативно), , (декартово произведение и внешнее соединение также являются коммутативными операциями). |
| Определение: |
| Ассоциативность — свойство . Пример: , , (из теории множеств), , (внешние соединения и декартово произведение являются ассоциативными операциями). |
Базис операций
- Унарные операции (projection, filter и переименование)
- Объединение и разность
- Декартово произведение
- Операции над данными (расширение и агрегирование)
Остальные привычные операции выразимы из этого базиса, например
Ограничения реляционной алгебры
- Не все операции представимы (например, транзитивное замыкание)
- Следует, что РА не эквивалентна машине Тьюринга
- Эквивалентность выражений алгоритмически неразрешима
Применимость
- Внутри БД для упрощения запроса и оптимизации плана выполнения
- Для запросов, невыразимых в SQL непосредственно (таких как деление и полусоединения)
Реляционная алгебра и SQL
Унарные операции
Проекция
Если нужно дублировать строки с одинаковыми значениями атрибутов, то из запроса надо удалить distinct.
select distinct from R
Фильтрация
select * from R where Condition
Переименование
select ..., a as b, ... from R
Операции над множествами
Объединение
select * from R1 union all select * from R2 -- с повторениями
Если нужно объединить без повторений, то необходимо убрать из запроса all
Пересечение =
select * from R1 intersect all select * from R2 -- с повторениями
Если нужно объединить без повторений, то необходимо убрать из запроса all
Разность
select * from R1 except select * from R2 -- с повторениями
Чтобы убрать повторения, необходимо добавить all после except
Операции над данными
Расширение
select *, expr as A from R
Агрегирование
select A, func(Q) as Q from R group by A -- A - сохраняемые атрибуты, func(Q) - агрегирующая функция select count(*)... -- подсчёт количества строк select count(distinct *)... -- подсчёт различных строк select count(q)... -- подсчёт не null атрибутов ... having Condition -- фильтрация после агрегации ... order by Attrs -- сортировка
Соединения
Полное
select * from R1 cross join R2 select * from R1, R2
Естественное
select * from R1 natural join R2 select * from R1 inner join R2 using (A) select * from R1 inner join R2 on R1.A = R2.A
Внешние
select * from R1 [full] outer join R2 on select * from R1 left [join] R2 on select * from R1 right [join] R2 on
Полусоединений нет
Структура SQL-запроса
SQL-запрос иммеет вид
select
... as ..., ... as ... -- и
from
xxx join on ... --
...
xxx join on ... --
where
... --
где — таблица или подзапросы
Примеры
- Пусть дана таблица `Persons (Id, Name, Birthday, MotherId, FatherId)` и требуется получить дни рождения родителей — `(Name, FatherBirthday, MotherBirthday)`.
select
p.Name as Name
f.Birthday as FatherBirthday
m.Birthday as MotherBirthday
from
Persons p
inner join Persons f on p.FatherId = f.id
inner join Persons m on p.MotherId = m.id
- Подзапросы: например, найти людей, у которых родители родились в один день `Name`.
select p.Name as Name
from (предыдущий запрос текстом)
where p.MotherBirthday = p.FatherBirthday
- Сложный запрос: например, дана таблица `Persons (Id, Name, MotherId, FatherId)` и требуется определить для каждого человека имя его родителя — `(Name, ParentName)`.
select p.Name as Name, f.Name as ParentName
from Persons p
inner join Persons f on f.FatherId = m.Id
union
select p.Name as Name, m.Name as ParentName
from Persons p
inner join Persons m on p.MotherId = m.Id
Литература
- Дейт К. Введение в системы баз данных
- Уидом Д., Ульман Д. Основы реляционных баз данных